배경
 |  |  |
이번 시즌은 매칭 신청 기간 동안 1:1과 3:3 미팅에 대해 참가 신청을 받은 뒤, 매칭 알고리즘으로 매칭한 결과를 주말동안 공개하는 방식으로 운영하였다. 특히 매칭 결과 조회는 발표 당일 대규모 트래픽이 몰릴 것으로 예상되었고, 이를 효율적으로 처리하기 위해 API를 지속적으로 개선해야 했다.
요구사항 변경
시즌5에서는 사용자 경험 개선을 위해 매칭 결과 공개 방식이 변경되었다. 기존에는 매칭 결과를 하나의 페이지에서 한번에 보여줬지만, 이번 시즌에는 세 페이지에 걸쳐서 단계적으로 공개하는 방식으로 변경됐다. 이에 따라 매칭 결과 조회는 아래의 절차로 진행되었다.
- 신청 내역 조회: 사용자의 매칭 신청 내역(1:1 또는 3:3)을 확인
- 매칭 성공 여부 조회: 매칭 성공/실패 여부를 확인
- 상대 정보 확인: 매칭된 상대의 정보와 메시지(편지) 확인
도전 과제
데이터베이스의 복잡성
 ERD
ERD
매칭 API는 여러 테이블 간의 복잡한 관계를 처리해야 했다. 주요 테이블은 다음과 같다.
meeting_user: 유저의 기본 정보.user_information: 유저의 세부 정보.meeting_team: 유저의 시대팅 신청 여부를 팀 단위로 관리.user_team:meeting_user와meeting_team간의 중간 테이블match: 매칭 성공한 팀 정보를 저장.payment: 결제 기록.
이처럼 여러 테이블 간의 관계가 얽혀 있어 쿼리 작성에 어려움이 있었다.
대규모 트래픽 대비
매칭 결과가 발표되는 시점에는 수백명에서 천명 사이의 사용자가 한꺼번에 매칭 결과를 조회할 것으로 예상되었다. 하지만 API 구조나 데이터베이스 쿼리를 비효율적으로 설계할 경우 서버에 문제가 생기고 유저에게 안좋은 경험을 줄 수 있었다.
초기 구현
설계 전략
시즌5에서는 대규모 트래픽을 대응하기 위해 다음과 같은 전략을 수립했다.
- 단계적 데이터 로딩
- 필요한 정보만 단계별로 조회하여 서버 부하 감소
- 각 API별 독립적인 캐싱 적용 가능
- 캐싱 전략 도입
- Redis를 활용한 매칭 결과 캐싱
- API 응답 데이터를 캐시하여 DB 부하 감소
- 내부적으로 API 재사용
- 데이터베이스 최적화
- 불필요한 JOIN 제거
- 쿼리 개선
API 구조 설계
기존 시즌4의 단일 엔드포인트 구조에서 벗어나, 각 단계별로 독립적인 API를 설계했다. 이는 약 1,000명의 사용자가 동시에 매칭 결과를 조회할 것으로 예상되는 상황에서, 서버의 부하를 분산시키기 위함이었다.
기존 API 구조 (시즌4)
GET /api/match1 2 3 4 5 6 7
@GetMapping("") fun getMatchedMeetingTeamInformation( @AuthenticationPrincipal userDetails: UserDetails, ): ResponseEntity<MatchInformationResponse> { return ResponseEntity.status(HttpStatus.OK) .body(matchingService.getMatchedMeetingTeam(userDetails.username.toLong())) }
새로운 API 구조
GET /api/match/me/participations: 미팅 신청 내역 조회GET /api/match/teams/{meetingTeamId}/result: 매칭 결과 조회GET /api/match/{matchId}/partner: 매칭 상대 정보 조회
캐싱 적용
각 API 호출시 서비스 계층에서 다른 메소드를 재사용하여 기존에 캐시된 데이터를 활용하고자 하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
@Service
@Transactional(readOnly = true)
class MatchingService() {
@Cacheable(value = ["meeting-participation"], key = "#userId", unless = "#result == null")
fun getUserMeetingParticipation(userId: Long): MeetingParticipationResponse {
...
}
@Cacheable(value = ["match-result"], key = "#meetingTeamId", unless = "#result == null")
fun getMatchResult(userId: Long, meetingTeamId: Long): MatchResultResponse {
// 미팅 신청 여부 확인
val participation = getUserMeetingParticipation(userId)
...
}
@Cacheable(
value = ["partner-info"],
key = "#matchId + ':' + #userId",
unless = "#result == null"
)
fun getMatchedPartnerInformation(
userId: Long,
matchId: Long
): MeetingTeamInformationGetResponse {
val matchResult = getMatchResult(userId, teamType)
...
}
}
문제점
API 설계상의 문제
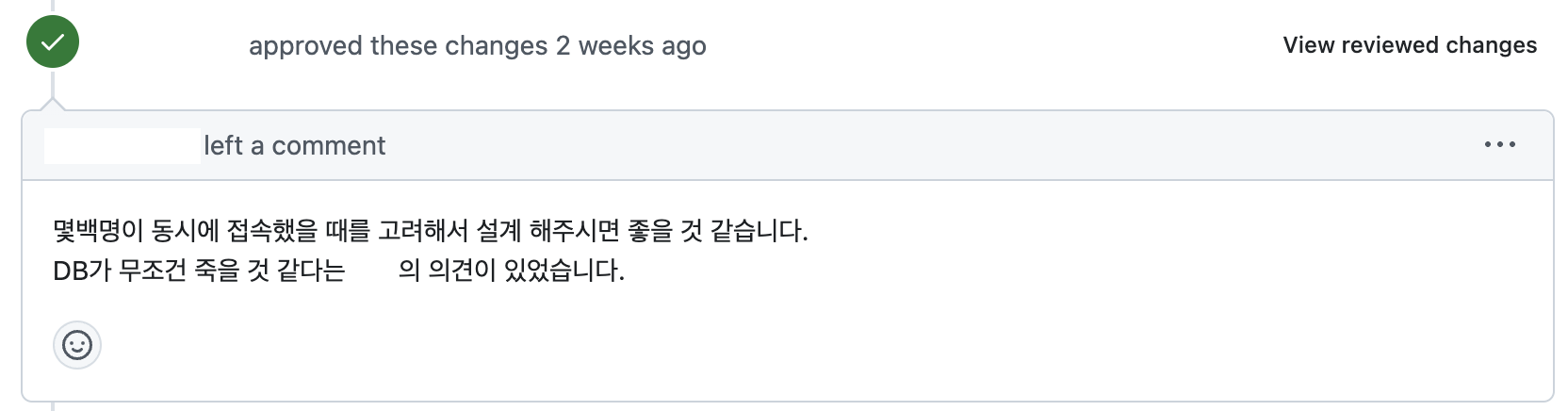
처음 설계한 3단계 API 구조에서는 각 단계가 이전 단계의 응답값에 의존하는 문제가 있었다. 예를 들어, 상대방 정보를 조회하기 위해서는 먼저 신청 내역을 조회하고, 그 결과로 받은 meetingTeamId로 매칭 결과를 조회한 뒤, 다시 그 결과로 받은 matchId로 상대방 정보를 조회하는 식으로 총 세 번의 API 호출이 필요했다.
1
2
3
4
5
6
7
8
1. GET /api/match/me/participations
→ meetingTeamId 획득
2. GET /api/match/teams/{meetingTeamId}/result
→ matchId 획득
3. GET /api/match/{matchId}/partner
→ 최종적인 상대방 정보 획득
이러한 구조는 다음과 같은 문제를 야기했다.
- 불필요한 API 호출 증가
- 프론트엔드에서의 복잡한 상태 관리
- API 의존성으로 인한 에러 처리 복잡성
 Pull Request에서 받은 피드백
Pull Request에서 받은 피드백
또한 위 피드백에서와 같이 각 API가 필요한 데이터를 개별적으로 조회하다 보니 동일한 테이블을 반복해서 조회하는 문제가 있었다. 여러 테이블을 JOIN하는 복잡한 쿼리도 API마다 중복 실행됐다. 이는 수백 명의 사용자가 동시에 매칭 결과를 조회할 것으로 예상되는 상황에서 데이터베이스에 심각한 부하를 줄 수 있었다.
캐싱 구현의 문제
초기에는 위에서처럼 서비스 계층에서 @Cacheable을 적용한 메소드를 다른 메소드가 호출하는 구조로 설계하였다. 하지만 API 호출 시 캐싱이 제대로 동작하지 않는 문제가 발견됐다. @Cacheable의 동작 원리에 대해 충분히 이해하지 못한 채로 사용한 것이 원인이었다.
Spring AOP와 프록시
스프링 AOP(Aspect Oriented Programming)는 핵심 비즈니스 로직과 부가 기능을 분리하여 관리하는 프로그래밍 방식이다. 여기서 실제 객체를 감싸고 있는 래퍼(Wrapper) 객체인 프록시가 실제 객체 대신 요청을 처리한다.
@Cacheable과 같은 AOP 기반의 어노테이션을 사용하면, 스프링은 해당 클래스의 프록시 객체를 생성한다. 이 프록시 객체는 메소드 호출을 가로채서 캐시 처리와 같은 부가 기능을 수행한 뒤, 필요한 경우에만 실제 객체의 메소드를 호출한다.
캐싱 동작 방식
다음은 @Cacheable을 사용한 예시 코드이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
@Service
class MatchingService(
private val matchingRepository: MatchingRepository
) {
@Cacheable(value = ["matching"])
fun getMatchingResult(id: Long): MatchingResult {
return matchingRepository.findById(id)
}
fun processMatching(id: Long): MatchingResult {
return getMatchingResult(id)
}
}
외부에서 getMatchingResult() 메소드를 호출할 때의 흐름은 다음과 같다.
- 클라이언트가 프록시 객체의
getMatchingResult()호출 - 프록시가 캐시에서 데이터 조회 시도
- 캐시에 데이터가 있으면 즉시 반환
- 캐시에 데이터가 없으면 실제 객체의 메소드를 호출하여 데이터를 조회하고 캐시에 저장
하지만 같은 클래스 내부에서 호출(processMatching())할 때는 다음과 같이 동작한다.
processMatching()이getMatchingResult()직접 호출- 프록시를 거치지 않고 실제 객체의 메소드가 바로 실행됨
- 캐시 처리가 수행되지 않음
해결 방법
이 문제를 해결하기 위한 방법은 크게 두 가지가 있다.
- 캐시 처리를 별도의 클래스로 분리
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
@Service class CacheableMatchingService( private val matchingRepository: MatchingRepository ) { @Cacheable(value = ["matching"]) fun getMatchingResult(id: Long): MatchingResult { return matchingRepository.findById(id) } } @Service class MatchingService( private val cacheableService: CacheableMatchingService ) { fun processMatching(id: Long): MatchingResult { return cacheableService.getMatchingResult(id) } }
- 자기 자신의 프록시 객체를 주입받아 사용 (Self-Injection)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
@Service class MatchingService( @Autowired private val self: MatchingService, private val matchingRepository: MatchingRepository ) { @Cacheable(value = ["matching"]) fun getMatchingResult(id: Long): MatchingResult { return matchingRepository.findById(id) } fun processMatching(id: Long): MatchingResult { return self.getMatchingResult(id) } }
개선 사항
API 구조 재설계
가장 먼저, 각 메소드가 독립적으로 동작하도록 API 구조를 변경했다. 즉, 하나의 메소드가 다른 메소드를 호출하지 않도록 변경하고, 엔드포인트 간의 의존성을 최소화했다.
우선 API 엔드포인트 구조를 다음과 같이 변경했다.
- 신청 내역 조회:
GET /api/match/me/participations(기존과 동일) - 매칭 결과 조회:
GET /api/match/{teamType}/info
이렇게 하여 API 호출 간의 의존성을 제거하고 클라이언트 데이터 흐름을 간소화하였고 API 호출 횟수를 줄였다. 또 경로 파라미터로 미팅 유형(teamType)을 받아 리소스를 명확하게 구분하였으며 추후 시즌이 거듭될 경우를 고려하여 쿼리 파라미터로 시즌 정보(season)을 받도록 하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
@RestController
@RequestMapping("/api/match")
class MatchApi(
private val matchingService: MatchingService,
) {
@GetMapping("/me/participations")
fun getUserMeetingParticipation(
@AuthenticationPrincipal userDetails: UserDetails,
@RequestParam season: Int,
): ResponseEntity<MeetingParticipationResponse> {
val result =
matchingService.getUserMeetingParticipation(userDetails.username.toLong(), season)
return ResponseEntity.ok(result)
}
@GetMapping("/{teamType}/info")
fun getMatchInformation(
@AuthenticationPrincipal userDetails: UserDetails,
@PathVariable teamType: TeamType,
@RequestParam season: Int,
): ResponseEntity<MatchInfoResponse> {
return ResponseEntity.ok(
matchingService.getMatchInfo(userDetails.username.toLong(), teamType, season)
)
}
}
캐싱 전략 개선
캐싱 문제를 해결하기 위해 다음과 같은 방식을 도입했다.
@Cacheable적용 방식 수정- 캐싱 메소드를 다른 메소드에서 내부 호출하지 않고, API 레벨에서 직접 호출하도록 변경했다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
@Cacheable( value = ["meeting-participation"], key = "#season + ':' + #userId", ) fun getUserMeetingParticipation(userId: Long, season: Int): MeetingParticipationResponse { return matchedDao.findUserParticipation(userId, season) } @Cacheable( value = ["match-info"], key = "#season + ':' + #teamType + ':' + #userId", ) fun getMatchInfo(userId: Long, teamType: TeamType, season: Int): MatchInfoResponse { val userTeam = userTeamDao.findUserWithTeamTypeAndSeason(userId, teamType, season) ?: throw MeetingTeamNotFoundException() val meetingTeam = userTeam.team val hasValidPayment = meetingTeam.payments?.any { payment -> payment.status == PaymentStatus.SUCCESS } ?: false if (!hasValidPayment) { throw PaymentNotFoundException() } try { val match = getMatchByGender(userTeam.user, meetingTeam) val opponentTeam = getOpponentTeamByGender(userTeam.user, match) val opponentUser = getOpponentLeaderUser(opponentTeam) return MatchInfoResponse.toMatchInfoResponse( getOpponentUserInformationByTeamType(meetingTeam, opponentUser) ) } catch (e: MatchNotFoundException) { return MatchInfoResponse(false, null) } }
- 캐시 키 형식
meeting-participation::{season}:{userId}: 시대팅 신청 여부match-info::{season}:{userId}: 매칭 정보
1 2 3
127.0.0.1:6379> keys * 1) "meeting-participation::5:23" 2) "match-info::5:SINGLE:35"
- 캐시 워밍(Cache Warming) 도입
- 매칭 데이터를 미리 캐시에 적재하여 발표 시점에 대규모 트래픽의 캐시 미스(cache miss)로 인한 서버 과부하를 방지했다.
이를 위해 Admin API에 캐시 초기화를 수행하는 API를 구현하였다. (
POST /api/admin/cache/warmup)1 2 3 4 5 6 7
class AdminApi() { @PostMapping("/cache/warmup") fun triggerCacheWarmup(@RequestParam season: Int): ResponseEntity<Unit> { adminService.warmUpCacheAsync(season) return ResponseEntity.status(HttpStatus.NO_CONTENT).build() } }
캐시 워밍 관련 함수는 비동기 처리를 하여 서버가 블로킹 되는 것을 방지했다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42
@Service class AdminService() { @Async fun warmUpCacheAsync(season: Int) { logger.info("[캐시 웜업 시작]") try { logger.info("[미팅 신청 정보 캐시 웜업 시작]") val allUsers = userRepository.findAll() allUsers.forEach { user -> user.id?.let { userId -> try { matchingService.getUserMeetingParticipation(userId, season) } catch (e: Exception) { logger.info("[미팅 신청 정보 캐시 웜업 실패] userId: $userId message: ${e.message}") } } } logger.info("[미팅 신청 정보 캐시 웜업 완료] 대상 인원: ${allUsers.size}") } catch (e: Exception) { logger.error("[미팅 신청 정보 캐시 웜업 전체 실패] message: ${e.message}") } try { logger.info("[매칭 결과 캐시 웜업 시작]") val participants = userTeamDao.findAllParticipantsBySeasonAndType(season) participants.forEach { participant -> try { matchingService.getMatchInfo(participant.userId, participant.teamType, season) } catch (e: Exception) { logger.info( "[매칭 결과 캐시 웜업 실패] userId: ${participant.userId} message: ${e.message}" ) } } logger.info("[매칭 결과 캐시 웜업 완료] 대상 인원: ${participants.size}") } catch (e: Exception) { logger.error("[매칭 결과 캐시 웜업 전체 실패] message: ${e.message}") } logger.info("[캐시 웜업 완료]") } }
개선 결과
위 개선사항을 적용한 결과, 아래와 같은 개선 효과를 확인할 수 있었다.
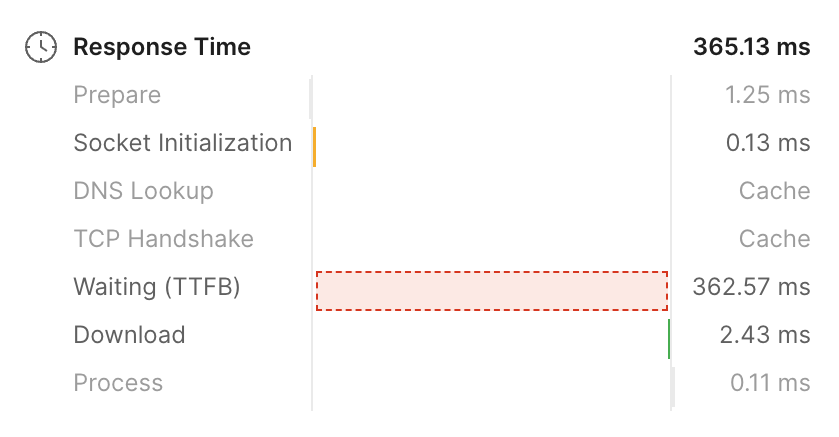
API 응답 시간 단축 (약 97%)
![image.png]() 기존 API 호출 시간
기존 API 호출 시간![image.png]() 개선된 API 호출 시간
개선된 API 호출 시간매칭 결과 발표 기간동안 안정적인 서비스 제공

마치며
이번 개선 작업 덕에 매칭 결과 발표 기간동안 다수의 트래픽이 발생했음에도 서버를 안정적으로 운영할 수 있었다. 특히 API 호출 수를 줄이고 캐싱을 활용한 전략이 데이터베이스 부하를 줄이는데 큰 도움이 되었다.
이번 작업은 복잡한 테이블 구조를 고려하여 쿼리를 최적화하고, 대규모 트래픽을 효과적으로 처리하기 위한 설계를 고민할 수 있었던 좋은 경험이었다. 특히 캐싱을 통해 성능을 최적화하는 과정에서 기존에 모호하게 알고 있던 캐시의 역할과 동작 방식을 명확히 이해할 수 있었다.