들어가며
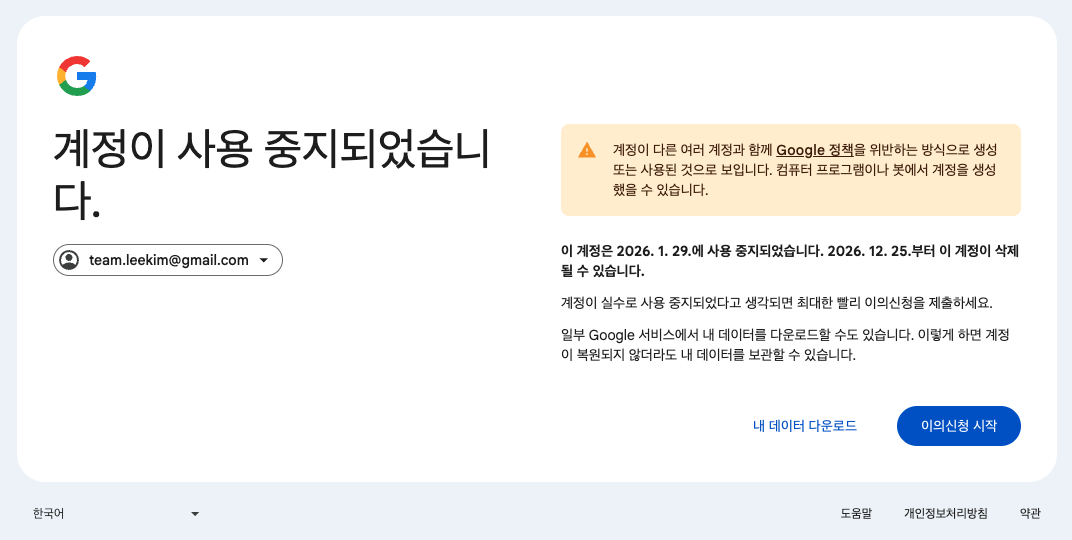
서비스를 운영하다 보면 외부 요인으로 인한 서비스 장애를 마주하곤 한다. 1월 29일 오후 5시, 팀 계정으로 사용하던 Google 계정에 접속하자 로그아웃 상태와 함께 본인인증 화면이 나타났다. 인증을 시도하자 계정이 보안 정책 위반으로 정지됐다는 화면이 출력되었다. 이의신청만 가능하고 계정 복구 가능성은 알 수 없는 상황이었다.

뉴스낵의 콘텐츠 생성 파이프라인은 텍스트 요약부터 뉴스툰 생성, 오늘의 뉴스낵 생성까지 100% Google Gemini API에 의존하고 있었기에, 파이프라인 전체가 순식간에 중단됐다. 이는 특정 기업의 인프라에 완전히 종속되어 발생하는 전형적인 벤더 종속(Vendor Lock-in)의 부작용이었다.
문제를 인지한 직후부터 서비스 정상화를 위한 대응책 탐색에 착수했다.
첫 번째 선택지는 새 Google 계정을 생성해 우회 연동하는 것이었다. 코드를 수정하지 않아도 되는 가장 단순한 방법이었지만 즉시 기각했다. 정지 조치를 우회하기 위해 임의로 새 계정을 생성하는 것은 서비스 이용 약관(Terms of Service) 위반 소지가 있어 또 다른 예고 없는 계정 정지로 이어질 리스크가 컸다. 무엇보다 ‘왜 정지되었는가’라는 근본적인 원인을 해결한 것이 아니기 때문에, 언제 다시 파이프라인이 멈출지 모르는 시한폭탄을 안고 가는 미봉책에 불과했다.
두 번째 선택지는 OpenAI API로 전면 전환하는 것이었다. 하지만 이 역시 근본적인 해결책은 아니었다. 단순히 의존하는 대상을 Google에서 OpenAI로 바꿨을 뿐, 특정 프로바이더에게 시스템 전체의 생존이 달려 있는 단일 장애 지점(Single Point of Failure, SPOF) 구조는 그대로 유지되기 때문이다. OpenAI에서도 서버 장애가 발생하거나 계정이 정지된다면 동일한 사태가 반복될 것이었다.
최종적으로 내가 채택한 방식은 멀티 프로바이더(Multi-Provider) 구조를 구축하는 것이었다. 외부 AI API의 다운타임이나 계정 정지 같은 통제 불가능한 리스크로부터 서비스의 고가용성을 지키려면 벤더 종속성을 물리적으로 끊어내야만 했다. 즉, 핵심 비즈니스 로직을 특정 AI 벤더로부터 완전히 격리하고, 한 프로바이더에 장애가 발생하면 즉각적으로 대체 프로바이더로 전환할 수 있는 회복 탄력성을 시스템 레벨에서 확보하고자 했다.
따라서 어떤 프로바이더에 장애가 발생하더라도 환경변수 교체만으로 즉시 다른 프로바이더로 전환할 수 있는 멀티 프로바이더 팩토리 패턴을 구축하기로 결정했다. 결정 직후 바로 설계에 착수했다.
1. 아키텍처 설계: AIProviderFactory 기반의 프로바이더 전환
가장 먼저 하드코딩되어 있던 모델 호출 객체를 분리해야 했다. LangChain의 일관된 인터페이스를 활용하여, 환경변수(AI_PROVIDER) 설정 하나로 어떤 클라이언트 구현체를 사용할지 결정하는 AIProviderFactory를 구현했다.
1
2
3
4
5
6
7
8
# app/core/config.py
class Settings(BaseSettings):
# 환경 변수로 실행 시킬 벤더사 결정
AI_PROVIDER: Literal["google", "openai"] = "google"
GOOGLE_CHAT_MODEL: str = "gemini-2.5-flash-lite"
OPENAI_CHAT_MODEL: str = "gpt-5-nano"
# ...
또한 선택된 프로바이더에 맞는 API Key가 없으면 서버 시작 자체를 차단하는 Fail-Fast 원칙을 Pydantic의 @model_validator로 구현했다. 잘못된 설정으로 서버가 실행되어 나중에 런타임 에러를 만나는 것보다, 시작 시점에 즉시 실패하는 편이 운영 안정성에 훨씬 유리하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# app/core/config.py
class Settings(BaseSettings):
AI_PROVIDER: Literal["google", "openai"] = "google"
GOOGLE_API_KEY: Optional[str] = None
OPENAI_API_KEY: Optional[str] = None
@model_validator(mode='after')
def check_api_keys(self) -> 'Settings':
"""선택된 프로바이더에 맞는 API Key가 없으면 서버 시작 자체를 차단 (Fail-Fast)"""
if self.AI_PROVIDER == "google" and not self.GOOGLE_API_KEY:
raise ValueError("AI_PROVIDER=google이지만 GOOGLE_API_KEY가 설정되지 않았습니다.")
if self.AI_PROVIDER == "openai" and not self.OPENAI_API_KEY:
raise ValueError("AI_PROVIDER=openai이지만 OPENAI_API_KEY가 설정되지 않았습니다.")
return self
초기화 과정에서 API 연결 지연이나 키(Key) 파싱 에러로 인해 FastAPI 서버 전체가 비정상 종료되는 문제를 막기 위해, 단순 전역 변수 초기화가 아닌 지연 로딩 기법을 적용하여 호출 시점에 클라이언트를 메모리에 올리고 캐싱하도록 설계했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# app/engine/providers.py
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_openai import ChatOpenAI
class AIProviderFactory:
def __init__(self):
self._llm = None
self._image_client = None
def get_llm(self):
"""환경 변수에 따라 런타임에 LLM 객체를 갈아끼운다 (DI)"""
if not self._llm:
if settings.AI_PROVIDER == "google":
self._llm = ChatGoogleGenerativeAI(model=settings.GOOGLE_CHAT_MODEL)
elif settings.AI_PROVIDER == "openai":
self._llm = ChatOpenAI(model="gpt-5-nano")
return self._llm
텍스트 노드에서는 단순히 factory.get_llm()을 호출하는 것으로 벤더와의 종속성이 완전히 모듈로 분리되었고, 구조적 출력(with_structured_output)과 같은 LangChain 핵심 인터페이스도 두 벤더 모두 호환되어 정상적으로 재작동했다.
2. 이미지 생성 전략의 분기: Google vs OpenAI
텍스트 생성 로직은 LangChain 덕분에 인터페이스가 통일되어 쉽게 리팩토링됐다. 하지만 이미지 생성은 두 API의 사용 방식이 근본적으로 달라 전략 자체를 분기해야 했다.
- Google Gemini: 이전에 생성한 이미지를 레퍼런스로 넣는 기능 사용. 작화 일관성 확보 가능.
- OpenAI (
gpt-image-1.5): 레퍼런스 기능 미사용. Base64 인코딩 방식으로 응답. 4장 독립 병렬 생성만 가능.
1
2
3
4
5
6
7
8
9
10
11
12
13
# app/engine/nodes/ai_article.py (image_gen_node 내부)
if settings.AI_PROVIDER == "openai":
# OpenAI: 레퍼런스 기능 미사용 → 4장 독립 병렬 생성 (속도 중시)
tasks = [generate_openai_image_task(i, prompts[i]) for i in range(4)]
results = await asyncio.gather(*tasks, return_exceptions=True)
else:
# Google: 레퍼런스 기능 사용 → 1장 앵커 선생성 후 나머지 3장 참조 (일관성 중시)
anchor_image = await generate_google_image_task(0, prompts[0], ref_image=None)
tasks = [
generate_google_image_task(i, prompts[i], ref_image=anchor_image)
for i in range(1, 4)
]
results = await asyncio.gather(*tasks, return_exceptions=True)
계정 복구 후에도 이 분기 코드는 유지했다. 향후 Circuit Breaker가 Google을 OPEN 상태로 판단하면 .env에서 AI_PROVIDER=openai로 변경하는 것만으로 즉시 OpenAI 전략으로 전환할 수 있는 구조이기 때문이다.
3. 객체 규격의 불일치: 이기종 SDK PIL 캐스팅 방어
텍스트 생성 로직은 성공적으로 분리되었으나, 정작 이미지를 생성한 뒤 S3로 업로드하는 지점에서 런타임 에러가 발생했다.
1
ERROR: 14:44:39 - ... Error generating image 0: Image.save() got an unexpected keyword argument 'format'
문제는 이미지 파일을 파이썬 백엔드로 가져올 때 각 벤더가 제공하는 SDK 인터페이스의 파편화였다. OpenAI SDK가 반환한 Base64 데이터를 파이썬 표준 라이브러리인 PIL.Image 형태로 생성하는 것과 달리, Gemini SDK의 추상화 메서드인 part.as_image()가 반환하는 컨테이너 클래스는 표준 PIL 객체의 규격을 100% 준수하지 않았다. save() 함수 파라미터를 제대로 인식하지 못해 백엔드 I/O 작업 중 충돌이 발생했다.
해결 방법: 가장 낮은 레벨(Raw Bytes)에서의 강제 타입 통일
이처럼 외부 벤더 SDK의 불투명한 래퍼(Wrapper) 함수에 비즈니스 로직을 의존하면, 내부 구현이 바뀔 때마다 예기치 않은 문제 상황을 맞게 된다. 이를 해결하기 위해 SDK가 던져주는 추상화 객체(as_image())를 버리고, 가장 가공되지 않은 하위 레벨(Raw Bytes)의 인라인 데이터만을 추출하여 io.BytesIO로 감싼 뒤 PIL.Image 클래스로 직접 형변환했다.
1
2
3
4
5
6
7
8
9
10
11
12
# app/engine/tasks/image.py
# [수정 전 - SDK 메서드 의존으로 비표준적인 반환 객체 발생]
- img = next((part.as_image() for part in response.parts if part.inline_data), None)
# [수정 후 - Raw 바이트 데이터를 추출하여(inline_data.data) 표준 PIL 객체로 통일 강제 바인딩]
+ img_part = next((part.inline_data for part in response.parts if part.inline_data), None)
+ if img_part:
+ # 무조건 io.BytesIO를 경유하도록 명시, 어떤 프로바이더라 하여도 동일한 객체 기반으로 후속 처리 보장
+ img = Image.open(BytesIO(img_part.data))
+ return img
이 짧은 강제 변환 코드를 통해 시스템 내부에서는 OpenAI의 결과물이든, Google의 결과물이든 완전히 동일한 PIL.Image.open 규격으로 다룰 수 있게 되었다. 두 이기종 모델이 동일한 인터페이스로 처리되는 다형성을 확보한 것이다.
최종 결과물
이렇게 구축한 멀티 프로바이더 구조에서 OpenAI의 GPT Image 1.5 모델을 사용해 이미지를 생성한 결과는 아래와 같다. 전반적으로 프롬프트를 잘 반영하는 편이었으나, Google의 이미지 모델보다 한글 표현력은 확연히 떨어졌다.
 |  |
|---|---|
 |  |
마치며
구글 계정 정지라는 예측 불가능한 외부 장애가 팩토리 패턴 도입의 직접적인 계기였다. 단순히 OpenAI로 전면 전환하는 대신, 환경변수(AI_PROVIDER) 변경만으로 전환이 가능한 멀티 프로바이더 구조를 택한 결과 계정 정지 상황에서도 불과 7시간 만에 파이프라인을 재가동할 수 있었다.
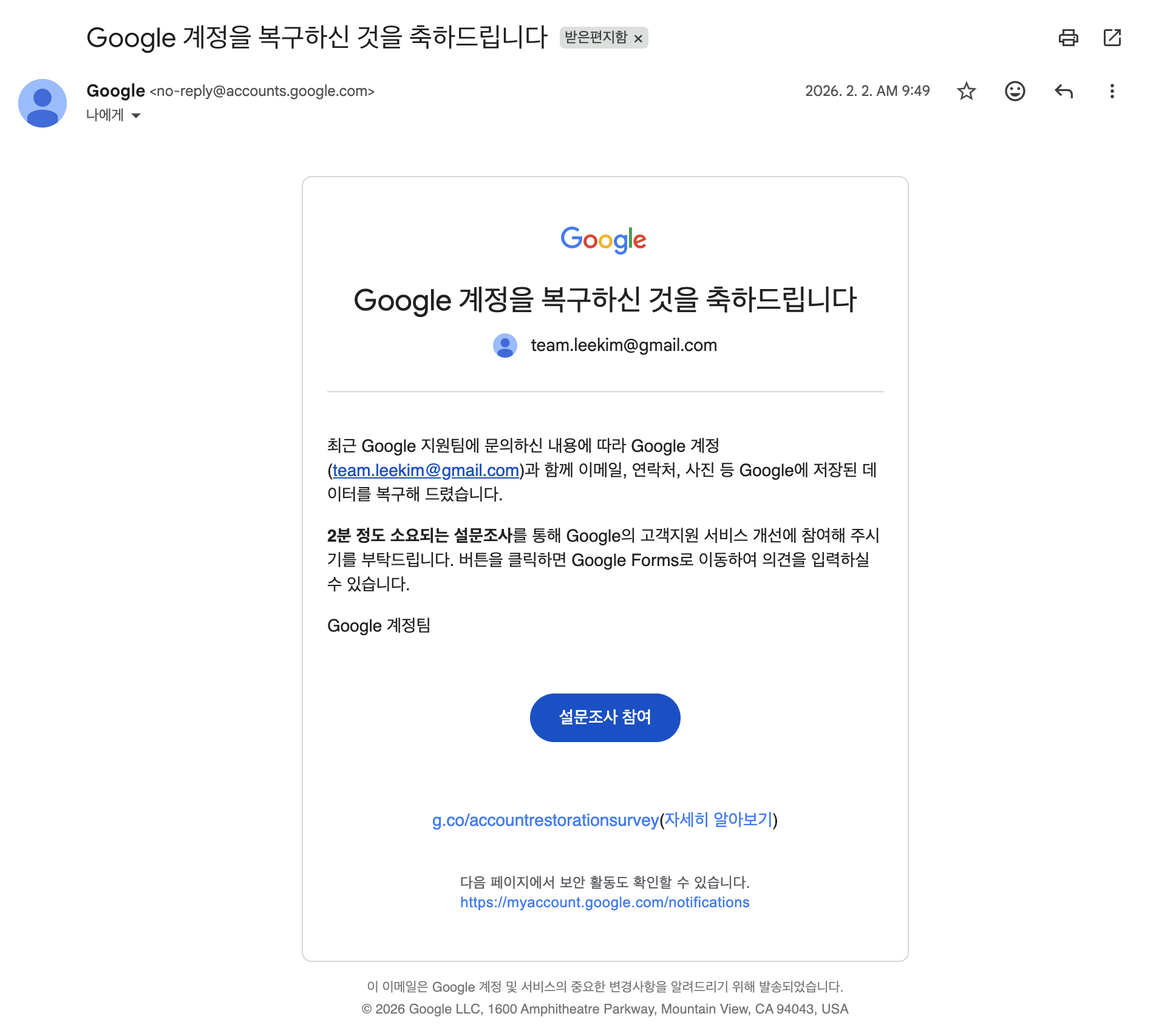
정지되었던 구글 계정은 이의신청이 받아들여져 2월 2일 오전에 정상적으로 복구되었다. 결과적으로는 며칠 만에 계정이 원상 복구된 셈이지만, 만약 팩토리 패턴을 통한 전환 구조를 구축하지 않고 무작정 구글의 조치만을 기다렸다면 해커톤의 핵심 개발 기간(1/29~2/2)을 완전히 허비해야만 했다. 이번 경험은 서드파티 의존성을 시스템적으로 통제하고 격리하는 것이 얼마나 중요한지 증명하는 확실한 사례가 되었다.
이기종 SDK를 통합할 때는 추상화된 SDK ‘편의 기능’보다 가장 원시적인 데이터 레벨인 바이트(Bytes) 단위에서 직접 타입을 통제하는 것이 시스템의 예측 가능성을 높인다는 것을 체감했다.
다만, 환경변수 변경과 재배포라는 수동 전환 방식은 장애 대응 속도에 한계가 있다. 이 문제를 시스템이 스스로 인지하고 자동으로 벤더를 페일오버하도록 추후 개선할 예정이다.