배경: 인프라 고정 비용 최적화의 필요성
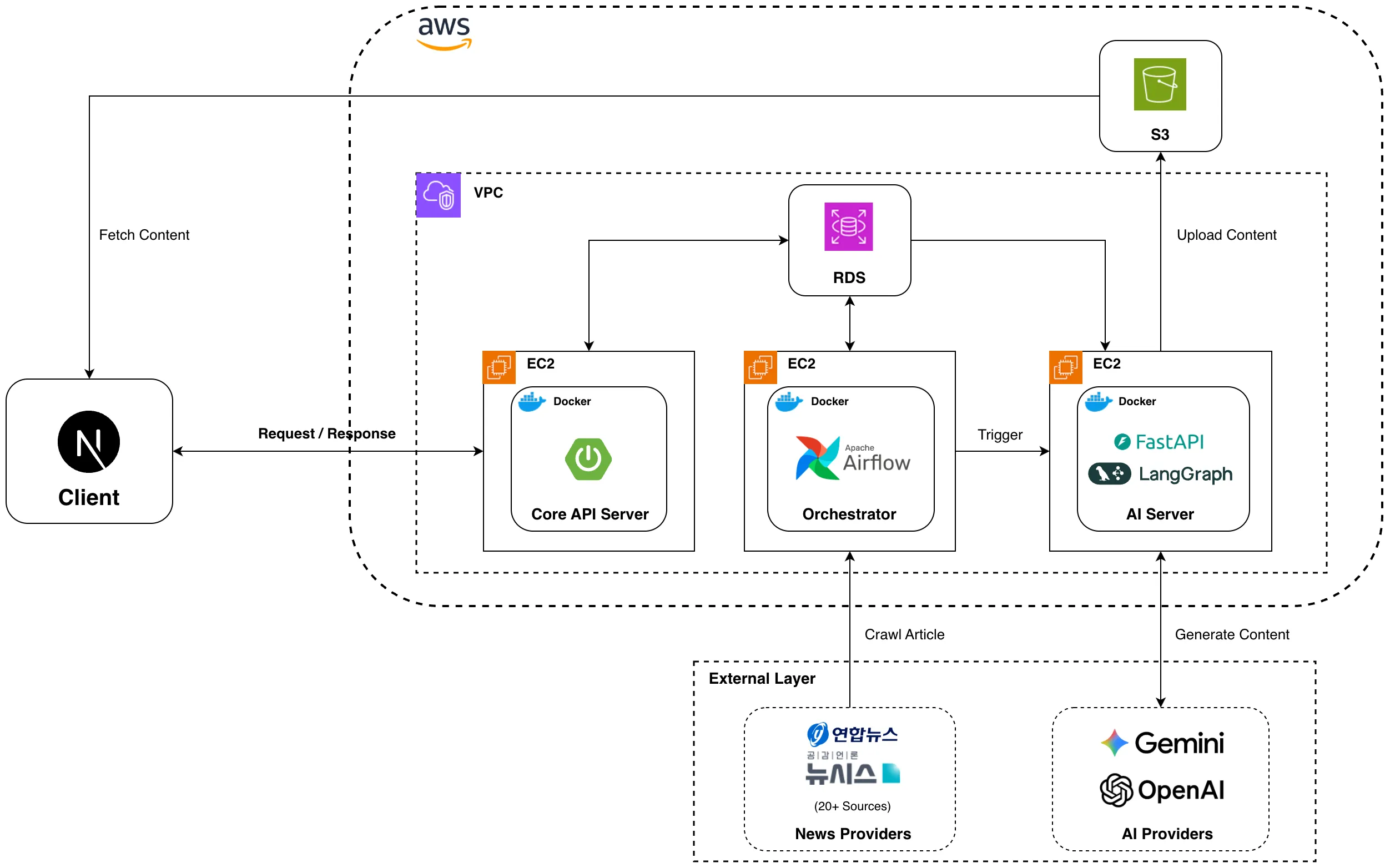 뉴스낵 시스템 아키텍처 (v1)
뉴스낵 시스템 아키텍처 (v1)
뉴스낵의 MVP 개발을 마무리하고 운영이 시작되자 인프라 고정 비용에 대한 고려가 필요해졌다. 초기에는 안정성을 명목으로 메인 API 서버(Spring Boot), AI 서버(FastAPI), 오케스트레이터(Airflow)를 각각 서로 다른 3대의 분리된 EC2 t3.small (x86 아키텍처, 2GB RAM)에 구성했다.
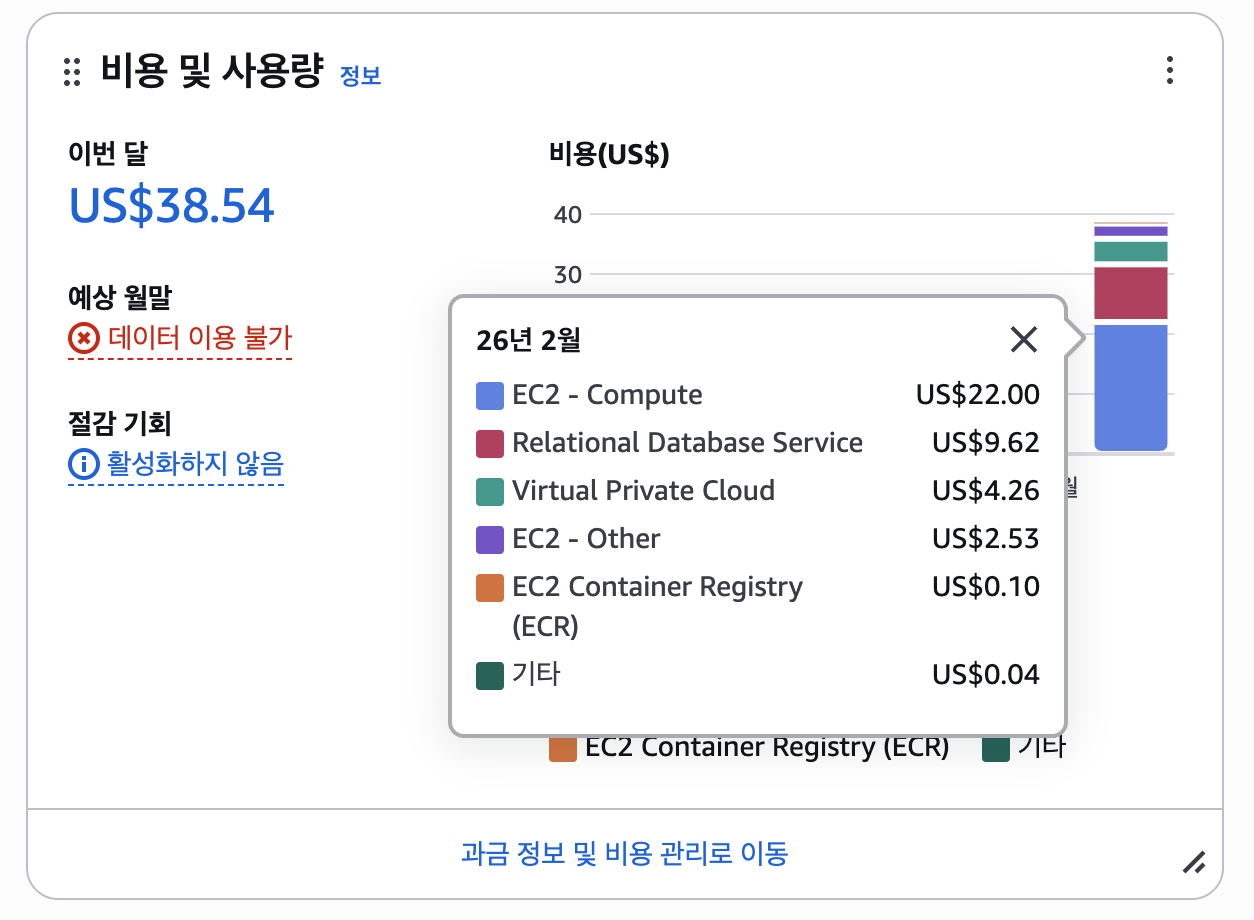
이대로 운영할 경우 예상되는 월 서버 비용은 약 $45(t3.small 시간당 약 $0.0208 × 24시간 × 30일 × 3대)에 달했다. 실제로 AWS 콘솔로 확인한 결과 현재까지의 사용 금액만 이미 $38를 넘어가고 있었다.
그러나 청구되는 비용 대비 실제 모니터링 지표는 비효율적이었다.
- 각 서버의 CPU/Memory 실사용률은 20%를 밑돌며 상당량의 유휴 자원이 발생했다.
- 3대의 서버 각각에서 OS 기본 프로세스가 선점하는 메모리(약 400~500MB)가 중복으로 낭비되고 있었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 메인 API 서버
[ec2-user@ip-10-0-10-126 ~]$ free -m
total used free shared buff/cache available
Mem: 1913 733 99 0 1081 1006
Swap: 0 0 0
# AI 서버
[ec2-user@ip-10-0-10-228 ~]$ free -m
total used free shared buff/cache available
Mem: 1913 564 105 0 1242 1164
# 오케스트레이터
[ec2-user@ip-10-0-7-80 ~]$ free -m
total used free shared buff/cache available
Mem: 1913 1235 403 0 274 516
Swap: 2047 977 1070
이에 자원 효율을 높이기 위해 인프라 통합 및 단일 환경 집적화를 진행했다.
1. 단일 인스턴스 통합
단일 EC2 호스트 안에 3개의 실행 환경을 모두 리소스 컨테이너 상에 통합 배치하기로 결정했다. 여기서 가장 핵심이었던 기술적 의사결정은 바로 x86 기반에서 ARM64 기반으로의 전면 마이그레이션이었다.
도입한 t4g.medium (2 vCPU, 4GB RAM) 인스턴스는, 동일 스펙인 t3.medium보다 클라우드 비용이 약 20% 저렴하며 전력 효율과 응답 성능은 훨씬 뛰어난 훌륭한 대안이었다. 이 통합을 통해 초기 산정 비용 월 $45를 월 $24로 (약 46% 감축) 절감했다.
2. GitHub Actions 네이티브 빌드 최적화: 크로스 컴파일 병목 해결
서버의 아키텍처를 x86에서 ARM64로 교체할 때 마주치는 거대한 진입 장벽은 바로 도커 이미지 빌드 파이프라인의 불일치다. 이전 프로젝트에서 x86 기반 깃허브 액션 러너 환경 위에 QEMU 에뮬레이터를 올려 ARM64 이미지를 크로스 빌드하다가, 컴파일 속도가 5배 가량 하락하여 CI/CD 파이프라인 효율이 크게 저하되는 문제가 있었다.

그러나 마침 2025년 1월부터 GitHub Actions가 공식적으로 Public Repository 대상 ARM64 Hosted Runner(ubuntu-24.04-arm)를 전면 무료 지원하기 시작했다.
.github/workflows/deploy.yml1 2 3 4 5 6 7
jobs: build: runs-on: ubuntu-24.04-arm steps: - name: Checkout Code uses: actions/checkout@v4
CI 파이프라인 러너 자체를 ubuntu-24.04-arm으로 전환하는 단 한 줄의 수정만으로, 기존 에뮬레이션 과정에서 발생하던 병목이 완전히 해소되었다. 결과적으로 기존 환경 대비 약 6배 향상된 빌드 속도를 확보하여 배포 소요 시간을 크게 단축했다.
3. 4GB 메모리 환경에서의 자원 격리 및 통제
물리 램 4GB의 제한된 서버 환경에 여러 백엔드 파이프라인을 모두 구성할 경우 발생할 수 있는 주요 문제는, 특정 컨테이너의 메모리 과점유가 OOM(Out of Memory)을 유발하여 호스트 전체 장애로 이어지는 것이다. 특히 대량의 오퍼레이션을 처리하는 Airflow 스케줄러가 파이프라인 배치 수행 시 메모리를 급격히 소모하는 현상을 제어하기 위해, Docker 내부 자원에 정밀한 리소스 리밋 시스템 체계를 구축했다.
docker-compose.yml1 2 3 4 5 6 7 8 9 10
airflow-scheduler: mem_limit: 2.2g mem_reservation: 700m ... newsnack-api: mem_limit: 1g mem_reservation: 500m newsnack-ai: mem_limit: 800m mem_reservation: 300m
핵심 전략은 “서비스 워크로드 상황에 맞춰 가용성을 유연하게 조정”하는 것이었다. 평소에는 Soft Limit(mem_reservation) 기준에 맞춰 가볍게 유지하다가 픽 타임 등 일시적인 부하 증가 시 유휴 리소스를 차용할 수 있게 Hard Limit(mem_limit)을 설정했다.
다만 이러한 구조에서는 Hard Limit의 총합이 5.4GB로 물리 RAM(4GB)을 초과하는 공격적인 오버커밋 환경이 조성된다. 그러므로 만일에 대비해 EC2 초기화 스크립트에 2GB 공간의 Swap 메모리 할당 조치를 포함시켰고, 이를 통해 OOM 프로세스 종료 현상을 메모리 레벨에서 방어하도록 이중 안전장치를 마련했다.
4. 통합 환경 트러블슈팅
이번 아키텍처 및 OS 환경 전환 과정에서 여러 계층(OS, 빌드 파이프라인, 도커 네트워크 등)에 걸쳐 크고 작은 문제에 직면했다. 인프라 이관 과정에서 겪었던 주요 병귀와 트러블슈팅 과정을 정리했다.
문제 1: Amazon Linux 2023의 Docker Compose 미지원
뉴스낵 개발 당시 EC2의 OS로는 AWS 환경에 최적화된 Amazon Linux 2023(AL2023)를 채택했다. 그러나 Docker Compose를 설치하려 하자 문제가 발생했다.
AL2023의 기본 패키지 매니저(dnf) 리포지토리에서는 docker-compose-plugin을 공식적으로 제공하지 않았다.
1
2
3
4
5
6
7
[ec2-user@ip-10-0-7-80 ~]$ sudo dnf install docker-compose-plugin -y
Last metadata expiration check: 0:03:03 ago on Thu Feb 5 01:32:18 2026.
No match for argument: docker-compose-plugin
Error: Unable to find a match: docker-compose-plugin
[ec2-user@ip-10-0-7-80~]$ docker compose version
docker: 'compose' is not a docker command.
See 'docker --help'
단순한 의존성 경로 변경만으로는 해결할 수 없었기에, 패키지 매니저 시스템을 우회하기로 결정했다. ARM64 아키텍처용 Docker Compose 바이너리를 직접 curl로 내려받아, 시스템 내부의 Docker 플러그인 디렉터리(/usr/libexec/docker/cli-plugins/docker-compose)에 직접 매핑시키고 실행 권한(chmod +x)을 부여했다. 이를 통해 플러그인 방식의 Docker Compose V2 환경을 안정적으로 구축할 수 있었다.
문제 2: 이미지 아키텍처 불일치 (Platform Mismatch)
마이그레이션 중 가장 먼저 직면한 오류는 베이스 이미지 아키텍처 미지원 문제였다. 백엔드 빌드에서 사용 중이던 eclipse-temurin:17-jre-alpine 이미지가 ARM 기반 러너 내에서 no match for platform을 띄우며 빌드 실패를 일으켰다. 해당 Base 이미지가 ARM64 아키텍처용 Alpine 버전을 지원하지 않은 것이 원인이었다.

신속히 대안을 찾아본 결과, AWS Graviton 환경에서 가장 뛰어난 호환성과 안정성을 검증받고 ARM 네이티브 빌드를 100% 공식 지원하는 amazoncorretto:17-alpine 으로 JRE 베이스 자체를 옮겨 플랫폼 종속성 문제를 성공적으로 해결했다.
문제 3: 단일 호스트 내부 도커 컨테이너 간 통신 에러 (Connection Refused)
1
2
3
[2026-02-17, 02:22:49 UTC] {http.py:248} WARNING - HTTPConnectionPool(host='localhost', port=8000):
Max retries exceeded with url: /ai-articles (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0xffffaac2a810>:
Failed to establish a new connection: [Errno 111] Connection refused')) Tenacity will retry to execute the operation

기존 분산 환경에서 localhost 기반으로 통신하던 모듈들을 하나의 EC2에 통합하자 네트워크 설정 충돌이 발생했다. Airflow 컨테이너에서 대상 AI 서버 컨테이너 측으로 HTTP 요청을 던질 때, 지속적으로 Connection refused로 태스크가 실패했다.
1
2
3
4
5
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
...
7cb1a760c737 newsnack-pipeline_default bridge local
ba52d39bb954 bridge bridge local
원인은 도커 컨테이너 네트워크가 서로 격리되어 있다는 점을 간과한 것이었다. Airflow는 Docker Compose를 통해 실행되면서 내부 전용의 newsnack-pipeline_default 사설망을 형성했다. 반면, AI 서버의 경우 CI/CD 스크립트에 명시된 명령을 통해 기본 bridge망 위에 독자적으로 배치되어 컨테이너 간 통신을 할 수 없는 상태였다.
따라서 AI 서버 CD 워크플로 스크립트를 수정해 컨테이너 네트워크 환경을 동일하게 연결하는 구문을 추가했다.
CD 스크립트1 2 3 4
docker run -d --name $CONTAINER_NAME \ -p 8000:8000 \ --network newsnack-pipeline_default \ ...
Airflow Connection에서 참조하는 API 엔드포인트 도메인 또한 localhost가 아닌 컨테이너 식별 이름(newsnack-ai)으로 교체하여 두 격리 환경 간의 통신 이슈를 완전히 해소했다.
문제 4: 호스트-컨테이너 간 디렉터리 마운트 권한 충돌 (Permission Denied)
단일 환경으로 통합하며 Airflow 컨테이너를 실행시켰을 때, logs 디렉터리 생성 과정에서 쓰기 권한 없음(Permission Denied) 에러가 발생했다.
이는 컨테이너 내부의 Airflow 프로세스 실행 주체가 일반 유저(UID 1000)인 반면, Docker 호스트(EC2) 시스템에서 볼륨으로 잡혀 자동 생성된 폴더는 소유자가 root로 강제 지정되어 발생하는 문제였다. 다음과 같이 호스트 디렉터리의 계정 소유권을 컨테이너와 동일한 UID로 변경하고 쓰기 권한을 인가하여 간단히 해결했다.
1
2
sudo chown -R 1000:0 ~/newsnack-pipeline/logs
sudo chmod -R 775 ~/newsnack-pipeline/logs
문제 5: Airflow 웹서버 워커 과다로 인한 메모리 누수 및 응답 지연
배포 직후 Airflow 웹 UI 접속이 매우 느려지거나 타임아웃이 발생하는 현상이 일어났다. docker stats와 서버 내부의 ps aux | grep gunicorn 명령으로 점검해 본 결과, 원인은 부분적인 메모리 고갈과 스로틀링에 있었다.
Airflow 웹서버는 구동 시 Gunicorn 워커 개수가 명시적으로 지정되지 않으면 기본 설정상 워커 프로세스를 4개 유지한다. 이로 인해 단일 워커만으로 가볍게 띄워도 충분한 규모임에도, 불필요한 프로세스들이 4GB 환경의 파이프라인 컨테이너 내부에서 무려 1.2GB 가까운 메모리 자원을 단독으로 점유하고 있었다.
이를 타개하기 위해 docker-compose.yml이 참조하는 환경변수(.env) 파일에 워커 수를 1개로 제한하는 설정을 추가했다.
.envAIRFLOW__WEBSERVER__WORKERS=1
이후 docker compose down 및 up -d를 통해 컨테이너 환경을 완전 재시작한 결과, 웹서버 컨테이너의 메모리 사용량이 1.2GB에서 약 755MB로 감소(약 37% 절감)하였으며, 여유 자원이 다시 확보되며 웹서버 접속 속도 문제도 해결되었다.
마치며
| 인스턴스 | 시간당 요금 | 개수 | 월별 요금 |
|---|---|---|---|
| t3.small | $0.0208 | 3 | $44.928 |
| t4g.medium | $0.0336 | 1 | $24.192 |
고가용성을 목적으로 설계되었던 기존의 물리 인프라 분산 체계를 탈피하여 시스템의 부하 특성을 분석한 뒤 서버 통합 및 자원 최적화 기법을 적용했다.
이를 통해 인프라 고정 비용을 약 46% 절감하고 관리 포인트를 단일화할 수 있었다. 기술 도구를 무분별하게 추가하기보다, 현 운영 환경의 제약 안에서 가장 타당한 아키텍처를 도출하는 경험이 됐다.