Computer Networking: A Top-Down Approach (7th Edition)를 정리한 글입니다.
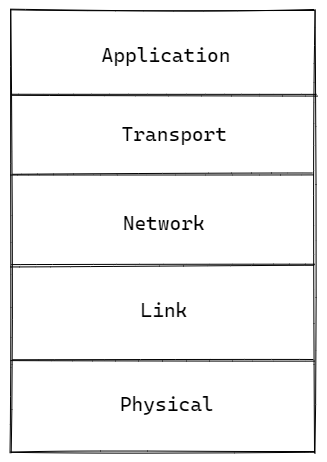
앞으로의 챕터들에서는 그림과 같이 애플리케이션 계층부터 아래 방향으로 알아볼 것이다.
이 장에서는 다음 내용을 공부할 것이다.
- 네트워크 애플리케이션의 개념과 구현하는 방법
- 주요 애플리케이션 계층 개념
- 웹, 이메일, DNS, P2P 파일 공유, 비디오 스트리밍 등 여러 네트워크 애플리케이션
- TCP와 UDP를 통한 네트워크 애플리케이션 개발
Principles of Network Applications
네트워크 애플리케이션 개발의 핵심은 서로 다른 종단 시스템에서 실행되고 네트워크를 통해 통신하는 프로그램을 작성하는 것이다. 따라서 여러 종단 시스템에서 실행될 소프트웨어를 짜야한다.
하지만 네트워크 코어 기기(라우터, 링크 계층 스위치 등)에서 실행되는 소프트웨어는 짤 필요가 없다. 이 기기들은 더 낮은 계층에서 동작하기 때문이다.
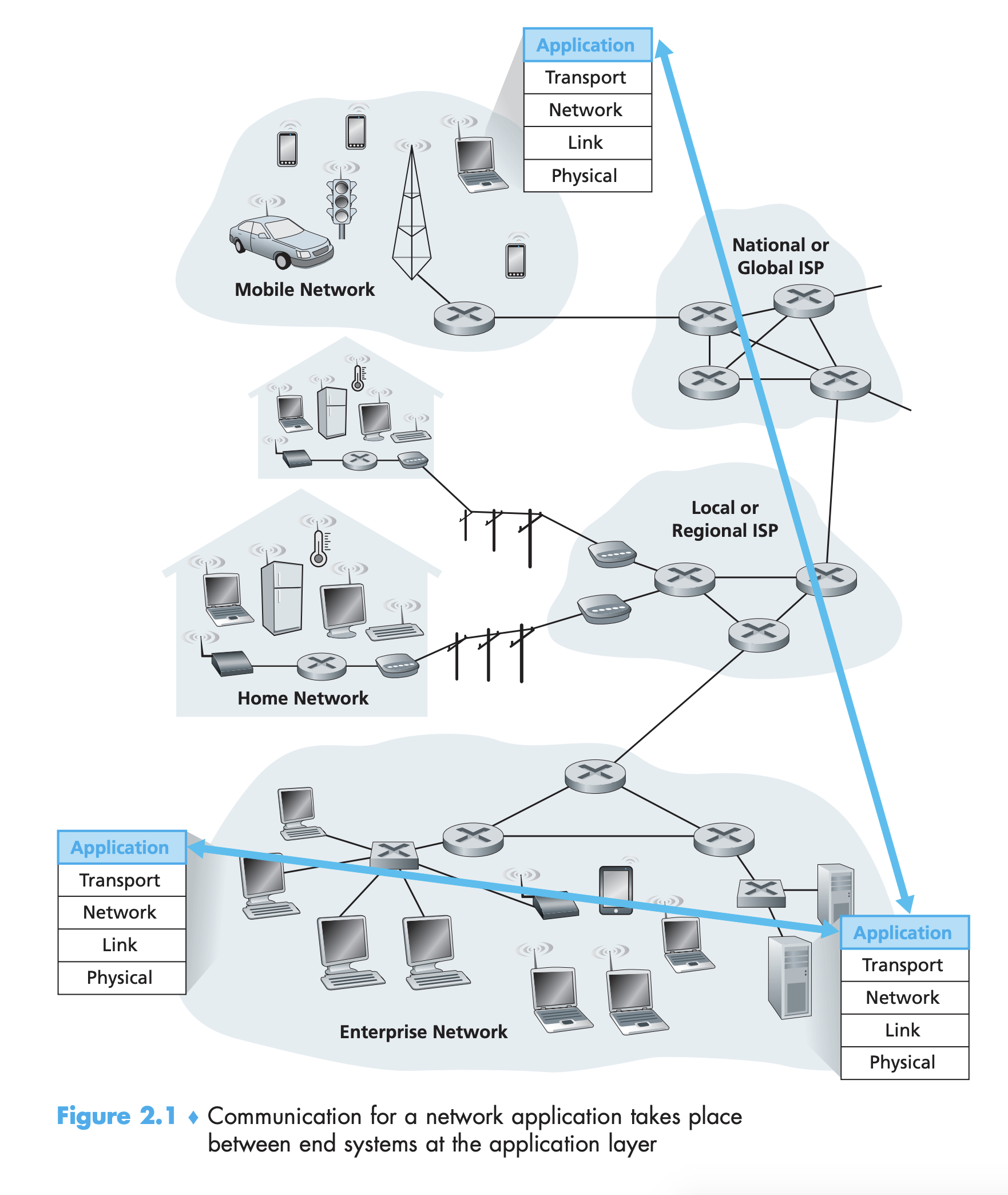
Network Application Architectures
소프트웨어 코딩을 하기 전에 전반적인 구조에 대한 계획을 세워야 한다.
네트워크 아키텍처는 고정되어 있고 애플리케이션에 특정한 서비스들을 제공한다.
애플리케이션 아키텍처는 애플리케이션이 다양한 종단 시스템에 걸쳐 어떻게 구조화되는지를 지시한다.
- 애플리케이션 아키텍처의 종류
- 클라이언트-서버(client-server) 아키텍처
- peer-to-peer (P2P) 아키텍처
클라이언트-서버 아키텍처 (그림 2.2(a))
- 서버
- 항상 켜진 호스트
- IP 주소라고 불리는 고정되고 잘 알려진 주소를 갖는다.
- 클라이언트
- 서버에게 서비스를 요청하는 호스트
- 클라이언트끼리는 직접 통신하지 않는다.
만약 웹 서버가 클라이언트 호스트로부터 객체를 요청받았다면, 해당 객체를 클라이언트에게 보냄으로서 응답한다.
ex. Web, FTP, Telnet, 이메일
- 데이터 센터
- 대형 사이트가 하나의 서버 호스트만 있다면, 많은 요청을 감당할 수 없다.
- 많은 서버 호스트
P2P 아키텍처 (그림 2.2(b))
데이터 센터의 전용 서버에 거의 의존하지 않는다.
피어(peer)라고 불리는 간헐적으로 연결된 호스트들과 직접적인 통신을 한다.
피어는 서비스 제공자의 소유가 아니고, 사용자들이 관리하는 데스크탑이나 노트북이다.
오늘날 트래픽이 집중되는 대부분의 애플리케이션들이 사용하는 방식
ex) 파일 공유(BitTorrent), 피어 지원 다운로드 가속(Xunlei), 인터넷 전화 & 비디오 회의(Skype)
- 자가 확장성(self-scalability)을 갖는다.
- 각 피어들이 파일을 요청해서 작업 부하를 만들어 내지만, 이들이 파일을 다른 피어들에게 배포해서 그 시스템에 서비스 능력을 추가해준다.
- 비용효율성(cost-effective)이 좋다.
- 엄청난 서버 인프라와 서버 대역폭을 갖출 필요가 없기 때문이다.
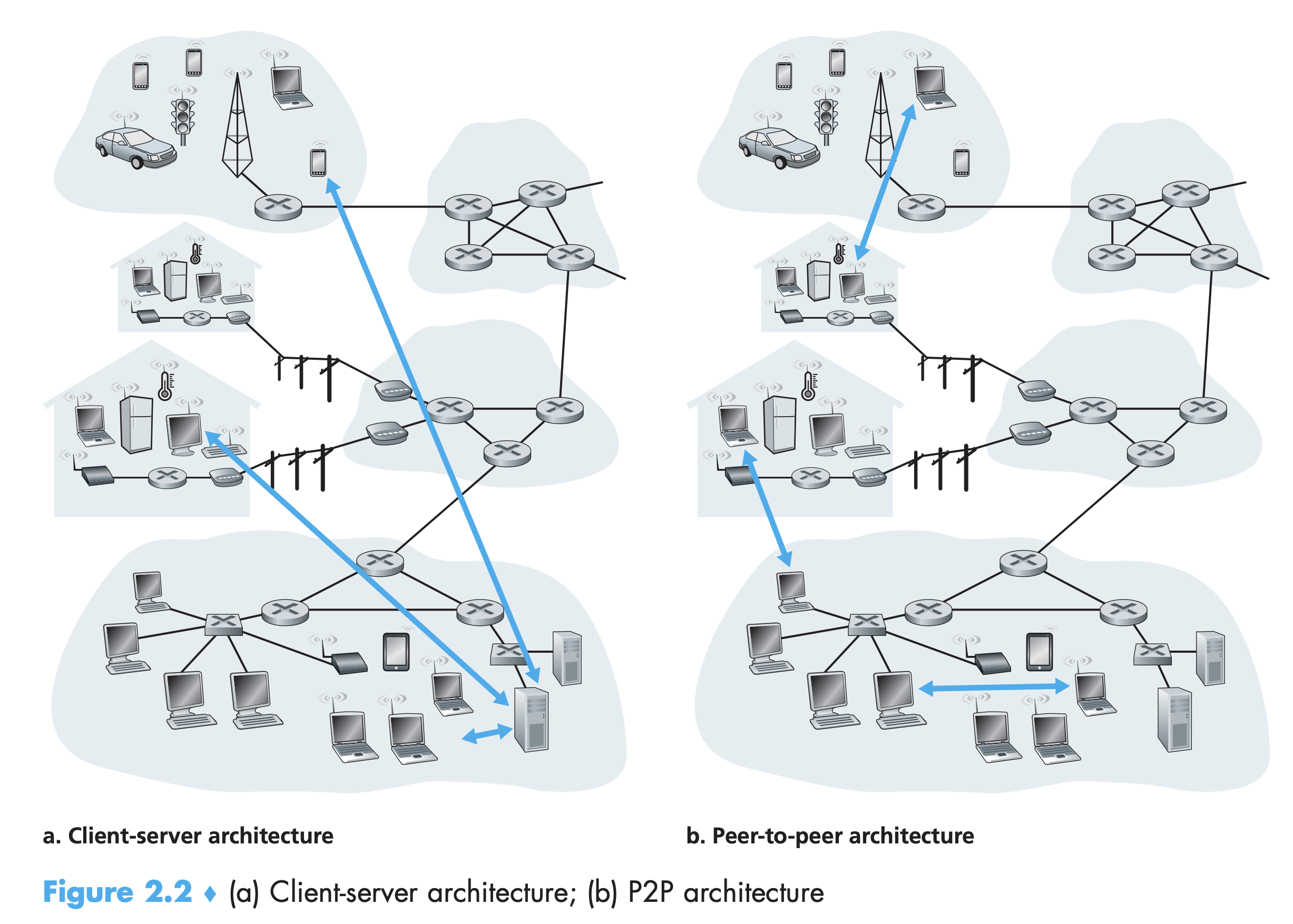
Processes Communicating
프로세스 : 운영체제에서 통신의 주체
- 프로세스 간 통신이 같은 종단 시스템에서 이루어지는 경우
- 프로세스 간 통신(interprocess communication)을 통해 이루어진다. 이때의 규칙은 종단 시스템의 운영체제를 따른다.
- 다른 종단 시스템에서 이루어지는 경우
- 컴퓨터 네트워크를 통해 메시지를 교환한다.
클라이언트, 서버 프로세스
네트워크 애플리케이션은 네트워크 너머의 서로에게 메시지를 보내는 프로세스의 쌍으로 구성되어 있다. 이들을 각각 클라이언트(client)와 서버(server)라고 부른다.
- 클라이언트 : 한 통신 세션에서 통신을 시작하는 프로세스
- 서버 : 세션을 시작하기 위해 접촉을 기다리는 프로세스
프로세스와 컴퓨터 네트워크 사이의 인터페이스
프로세스는 소켓(socket)이라고 불리는 소프트웨어 인터페이스를 통해 메시지를 네트워크로 보낸다.
그림 2.3은 두 프로세스가 인터넷 너머로 통신하는 모습을 표현한 것이다.
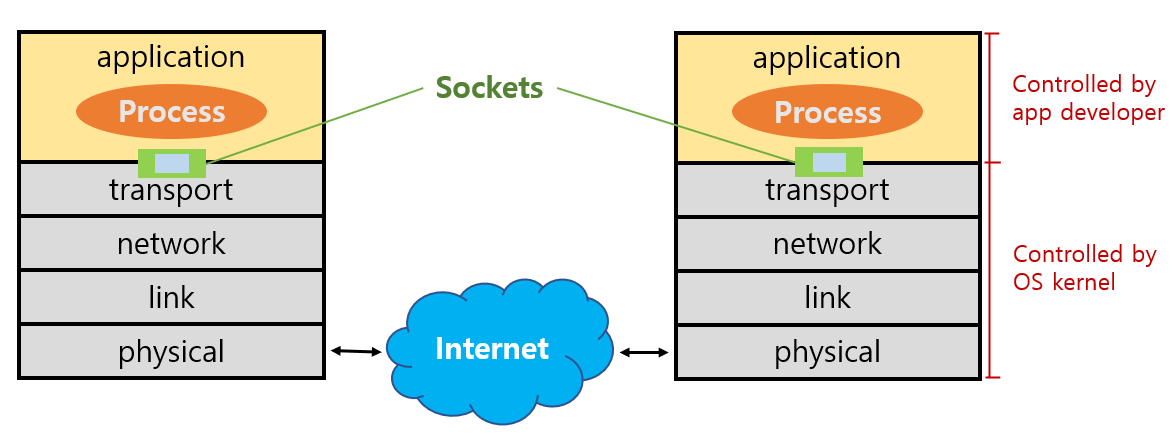
- 소켓
- 소켓은 호스트 내의 애플리케이션 계층과 통신 계층 사이의 인터페이스이다.
- 애플리케이션과 네트워크 사이의 API(Application Programming Interface)라고도 불린다.
- 애플리케이션 개발자가 통신 계층에서 관리하는 부분
- 통신 프로토콜의 선택
- 일부 전송 계층 매개변수(최대 버퍼, 최대 세그먼트 크기 등)를 고정하는 기능
프로세스 주소 지정(Addressing Processes)
한 호스트에서 실행되는 프로세스가 다른 호스트의 프로세스에게 패킷을 전송하려면 수신하는 프로세스는 주소를 가져야 한다.
프로세스를 식별하려면 다음의 두 가지 정보가 필요하다.
- 호스트의 주소
- 목적지 호스트에서 수신 프로세스를 특정해주는 식별자
인터넷에서 호스트는 IP 주소를 통해 식별된다.
호스트 내의 프로세스는 포트 번호(port number)를 통해 식별한다.
Transport Services Available to Applications
애플리케이션을 개발할 때, 사용 가능한 전송 계층 프로토콜 중 하나를 선택해야 한다.
이러한 선택을 하는 기준은 다음과 같다.
신뢰할 수 있는 데이터 전송 (Reliable Data Transfer, RDT)
데이터의 전달이 보장되는 경우 RDT를 제공한다고 한다.
통신 계층 프로토콜이 제공하는 중요한 것 중 하나는 프로세스 간의 RDT이다.
- loss-tolerant application
- RDT를 제공하지 않아도(=일부 데이터가 도착하지 않을 수 있음) 괜찮다.
- ex. 오비오/비디오를 통한 의사소통과 같은 멀티미디어 애플리케이션
처리량 (Throughput)
- 사용 가능한 처리량(available throughput)
- 송신 프로세스가 수신 프로세스에 비트를 전달할 수 있는 속도를 의미한다.
- 시간에 따라 바뀔 수 있다.
- 대역폭 민감 애플리케이션 (bandwidth-sensitive application)
- 처리량의 요구조건이 있는 경우
- 현재 많은 멀티미디어 애플리케이션이 갖는 형태
- 탄력적인 애플리케이션 (elastic application)
- 사용 가능한 처리량을 최대로 사용하거나 최소로 사용할 수 있다.
타이밍 (Timing)
데이터 전송에 빠듯한 시간 제약이 있는 모든 경우에 중요하다. ex) 인터넷 전화, 가상 환경, 화상 회의, 멀티 플레이어 게임 등
보안 (Security)
두 프로세스 간에 기밀성을 제공한다.
data integrity, end-point authentication 등의 특성도 제공한다.
Transport Services Provided by the Internet
인터넷(주로 TCP/IP)은 애플리케이션에 UDP, TCP의 두 가지 전송 프로토콜을 제공한다. 네트워크 애플리케이션을 새로 만들면 우선 이들이 제공하는 서비스를 보고 무엇을 사용할지를 선택해야 한다.
애플리케이션마다 필요한 서비스가 다르다.
| Application | Data Loss | Throughput | Time-Sensitive |
|---|---|---|---|
| File transfer/download | No loss | Elastic | No |
| No loss | Elastic | No | |
| Web documents | No loss | Elastic (few kbps) | No |
| Internet telephony/ Video conferencing | Loss-tolerant | Audio: few kbps-1Mbps Video: 10kbps-5Mbps | Yes: 100s of msec |
| Streaming stored audio/video | Loss-tolerant | Same as above | Yes: few seconds |
| Interactive games | Loss-tolerant | Few kbps-10kbps | Yes: 100s of msec |
| Smartphone messaging | No loss | Elastic | Yes and no |
TCP 서비스
애플리케이션이 전송 프로토콜로 TCP를 선택하면 다음의 서비스를 제공받는다.
- 연결 지향 서비스 (connection-oriented service)
- handshaking procedure : 애플리케이션 단에서 메시지가 이동하기 전에 클라이언트와 서버가 전송 계층 제어 정보(control information)를 교환한다.
- 이를 통해 클라이언트와 서버가 패킷이 갑작스럽게 쏟아질 것에 대비하게 한다.
- 이로 인해 두 프로세스의 소켓 사이에 TCP 연결이 생긴다.
- 연결은 전이중(full-duplex) 방식으로, 두 프로세스가 동시에 메시지를 서로에게 보낼 수 있다.
- 메시지 전송이 끝나게 되면 연결을 끊는다.
- handshaking procedure : 애플리케이션 단에서 메시지가 이동하기 전에 클라이언트와 서버가 전송 계층 제어 정보(control information)를 교환한다.
- 신뢰성 있는 데이터 전송 서비스 (reliable data transfer service)
- 모든 데이터를 오류 없이 올바른 순서대로 전송할 수 있다.
- 애플리케이션의 한 쪽에서 바이트 스트림을 소켓에 전달하면, TCP에 의존하여 동일한 바이트 스트림을 누락이나 중복 없이 수신 소켓에 전달할 수 있다.
- 혼잡 제어 메커니즘 (congestion-control mechanism)
- 송신자와 수신자 사이의 네트워크가 혼잡할 때, 프로세스의 송신을 제어한다.
- 통신 프로세스들만이 아니라 인터넷 전체적인 번영을 위해 필요하다.
UDP 서비스
UDP는 저비용, 경량 전송 프로토콜이며 다음의 최소한의 서비스만을 제공한다.
- 비연결 (connectionless)
- 신뢰할 수 없는 데이터 전송 서비스 (unreliable data transfer service)
- UDP는 메시지가 프로세스에게 수신될 것이라는 보장을 하지 않는다.
- 전송된 메시지가 뒤죽박죽으로 도착할 수도 있다.
- 혼잡 제어 메커니즘이 없음 (no congestion-control mechanism)
- UDP의 송신측에서 원하는 속도로 데이터를 아래 계층으로 보낼 수 있다.
인터넷이 제공하지 않는 서비스
오늘날의 인터넷은 시간에 민감한 애플리케이션에 만족스러운 서비스를 제공하지만, 타이밍이나 처리량을 보장해주지는 않는다.
그림 2.5는 일부 유명한 인터넷 애플리케이션에서 사용하는 전송 프로토콜을 보여준다.
| Application | Application-Layer Protocol | Underlying Transport Protocol |
|---|---|---|
| Electonic | SMTP [RFC 5321] | TCP |
| Remote terminal access | Telnet [RFC 854] | TCP |
| Web | HTTP [RFC 2616] | TCP |
| File transfer | FTP [RFC 959] | TCP |
| Streaming multimedia | HTTP (e.g., YouTube) | TCP |
| Internet telephony | SIP [RFC 3261], RTP [3550], proprietary (e.g., Skype) | UDP or TCP |
Application-Layer Protocols
애플리케이션 계층 프로토콜은 서로 다른 종단 시스템에서 실행되는 애플리케이션의 프로세스가 서로에게 메시지를 보내는 방법을 정의한다.
더 자세하게는 다음의 내용들을 정의한다.
- 교환되는 메시지의 유형 (요청 메시지, 응답 메시지)
- 다양한 메시지 유형들의 문법 (메시지의 필드, 필드가 설명되는 방법)
- 각 필드의 의미
- 프로세스가 메시지를 보내는 시간과 방법을 결정하는 규칙
The Web and HTTP
1990년대 초반까지 인터넷은 연구원, 교수, 대학생 등에 의해 사용되었지만 외부의 사람들에게는 알려지지 않았다. 그래고 1990년대 초에 World Wide Web이라는 주요 애플리케이션이 등장했다.
웹이 매력적인 이유는 사용자가 원하는 것을, 원하는 때에 받도록 한다는 것이다.
웹과 웹 프로토콜은 유튜브, 웹 기반 이메일, 모바일 인터넷 애플리케이션 등의 플랫폼 역할을 한다.
Overview of HTTP
HyperText Transfer Protocol (HTTP)
웹의 애플리케이션 계층 프로토콜
웹의 중심에 위치한다.
서로 다른 종단 시스템에서 실행되며 HTTP 메시지를 교환하는 클라이언트 프로그램과 서버 프로그램으로 나뉘어 구현된다.
웹 페이지는 객체(object)로 구성된다.
객체는 하나의 URL로 주소가 지정될 수 있는 파일(HTML 파일, JPEG 이미지 등)이다.
대부분의 웹 페이지는 한 개의 기본 HTML 파일과 여러 개의 참조된 객체로 이루어져 있다.
HTML 파일은 객체의 URL을 통해 페이지 상의 다른 객체를 참조한다.
각 URL은 두 가지 구성요소인 호스트명(hostname)과 객체의 경로명(path name)을 갖는다.
http://www.someSchool.edu/someDepartment/picture.gif이라는 URL이 있을 때, 호스트명은 www.someSchool.edu이고, 경로명은 /someDepartment/picture이다.
HTTP의 서버측을 구현하는 웹 서버는 웹 객체들을 보관한다.
HTTP는 웹 클라이언트가 웹 서버에 웹 페이지를 요청하는 방법과 서버가 웹 페이지를 클라이언트에게 전송하는 방법을 정의한다.
아래 그림은 클라이언트와 서버 사이의 상호작용을 나타낸다.
- 사용자가 웹 페이지를 요청한다.
- 브라우저가 HTTP 요청 메시지를 서버에게 보낸다.
- 서버는 해당 요청을 받고 해당 객체가 포함된 HTTP 응답 메시지로 응답을 보낸다.
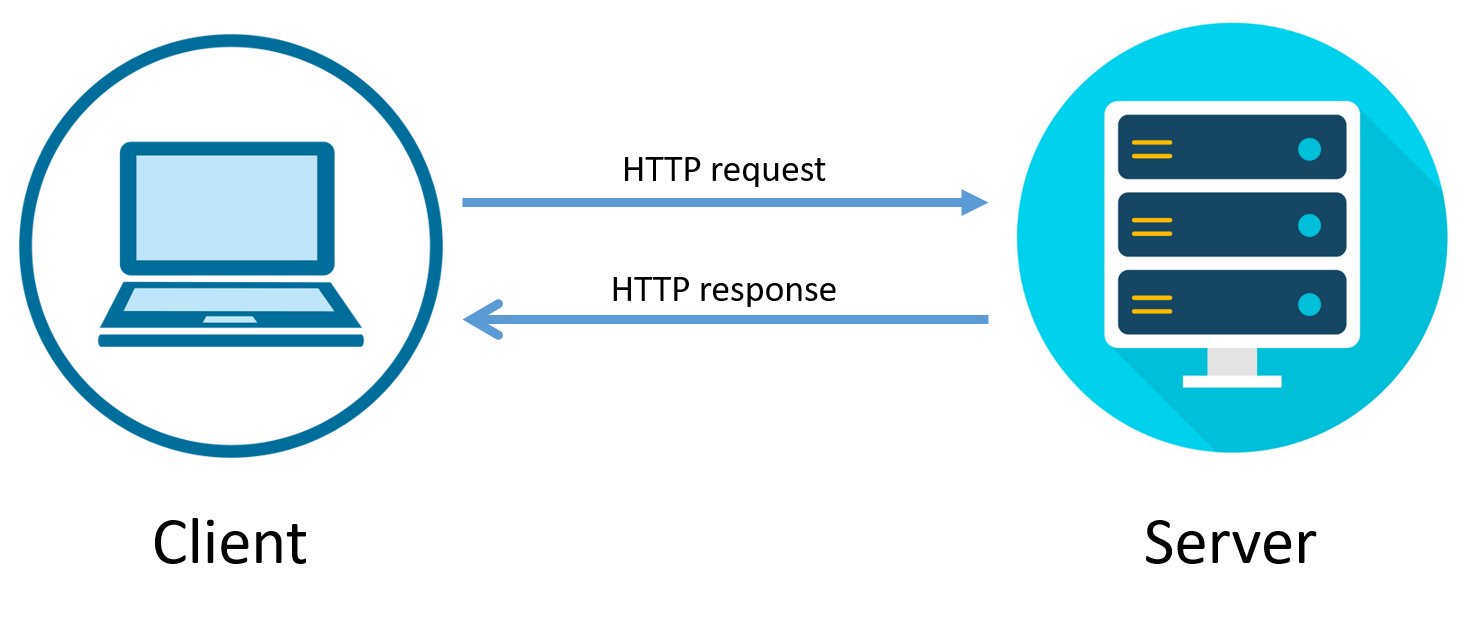
HTTP는 TCP를 기본 전송 프로토콜로 사용한다.
- stateless protocol
- 서버는 요청받은 파일을 클라이언트에게 전송하는 과정에서 클라이언트의 상태와 관련된 어떤 정보도 저장하지 않는다.
- 때문에 특정 클라이언트가 같은 객체를 두 번 요청하면 그냥 재전송한다.
Non-Persistent and Persistent Connection
클라이언트-서버 상호작용이 TCP를 통해 이루어질 때, 애플리케이션 개발자는 다음 두 가지 중 하나를 선택해야 한다.
- 각 요청/응답 쌍이 독립된 TCP 연결로 보내진다 : 비지속 연결(non-persistent connections)
- 모든 요청과 그에따른 응답이 동일한 TCP 연결을 통해 보내진다 : 지속 연결(persistent connections)
HTTP가 지속 연결 방식을 사용한다고 해도 각각의 클라이언트와 서버는 비지속 연결을 사용할 수 있다.
비지속 연결을 하는 HTTP
기본 HTML 파일과 10개의 JPEG 이미지로 구성된 페이지가 있고 11개의 객체가 모두 동일한 서버에 있다고 가정해보자. 또 기본 HTML 파일의 URL은 http://www.someSchool.edu/someDepartment/home.index라고 하자.
이때, 웹 페이지를 전송하기 위해 다음 과정이 진행된다.
- HTTP 클라이언트 프로세스가 포트 80에 있는 서버
www.someSchool.edu에게 TCP 연결을 시작한다.- 포트 80번은 HTTP의 기본 포트 번호이다.
- HTTP 클라이언트가 소켓을 통해 HTTP 요청 메시지를 서버에게 보낸다.
- 해당 메시지에
/someDepartment/home.index라는 경로명을 포함시킨다.
- 해당 메시지에
- HTTP 서버 프로세스는 소켓을 통해 요청 메시지를 받는다. 해당 프로세스는 저장소에서 객체를 찾아서 HTTP 응답 메시지 안에 캡슐화한다. 이후 소켓을 통해 클라이언트에게 메시지를 보낸다.
- HTTP 서버 프로세스는 TCP에게 TCP 연결을 끊으라고 한다.
- HTTP 클라이언트가 응답 메시지를 받는다. TCP 연결이 종료된다.
- 클라이언트는 메시지에서 HTML 파일을 추출하고 검사한다.
- 그 뒤에 10개의 JPEG 객체에 대한 참조를 찾는다.
- 각각의 참조된 JPEG 객체에 대해 앞의 1 ~ 4단계가 반복된다.
브라우저가 웹 페이지를 수신하면 이를 사용자에게 보여준다. 만약 브라우저가 다르다면 보여지는 모습도 다를 수 있다.
이 방식은 각 TCP 연결이 요청 메시지와 응답 메시지를 한 개씩만 전송한다. 따라서 위의 예시의 경우 11개의 TCP 연결이 생성된다. 이때, 각 TCP 연결이 병렬적으로 구성될지, 연달아 구성될지는 사용자의 설정에 따른다.
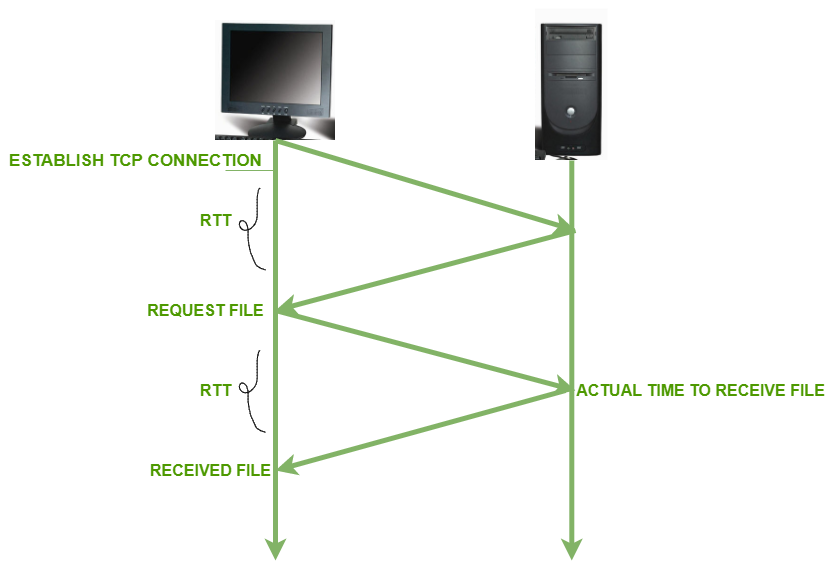
클라이언트가 기본 HTML 파일을 요청하고 완전히 수신하는데 걸리는 시간을 어림잡아 계산할 때 RTT라는 개념이 등장한다. (그림 2.7)
- round-trip time (RTT)
- 작은 패킷이 클라이언트에서 서버로 갔다가 클라이언트에게 되돌아오는데 걸리는 시간
- 패킷 전파 지연(propagation delay), 패킷 큐잉 지연(queueing delay), 패킷 처리 지연(processing delay)이 포함된다.
- 한 번의 연결에 RTT는 총 두 번이 존재한다.
- TCP 연결을 설립하기 위해
- 객체를 요청하고 받기 위해
지속 연결을 하는 HTTP
비지속 연결은 다음과 같은 단점을 갖는다.
- 각각의 요청된 객체마다 새로운 연결이 설립되어야 한다.
- 이러한 연결마다 TCP 버퍼가 할당되고 TCP 변수도 클라이언트, 서버 모두에 유지돼야한다.
- 이로 인해 웹 서버에 상당한 부담을 준다.
- 각 객체는 RTT 두 번의 전송지연을 겪는다.
HTTP 1.1 지속 연결을 사용하면, 서버는 응답을 보낸 후에도 TCP 연결을 끊지 않고 열어둔다.
이후에 같은 클라이언트와 서버에서 요청과 응답을 보낼 때, 같은 연결을 사용한다.
웹 페이지 전체가 하나의 TCP 지속 연결을 통해 이루어질 수 있다.
HTTP 기본 모드는 파이프라이닝을 통한 지속 연결을 사용한다.
- HTTP 파이프라이닝 (HTTP pipelining)
- HTTP/1.1의 기능
- 여러 HTTP 가 하나의 TCP 연결을 통해 응답을 기다리지 않고 보내질 수 있도록 한다.
HTTP Message Format
HTTP 메시지는 요청 메시지와 응답 메시지 두 종류가 있다.
HTTP Request Message
다음은 일반적인 HTTP 요청 메시지이다.
1
2
3
4
5
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/5.0
Accept-language: fr
보다시피 메시지는 ASCII 문자로 쓰여진다.
다섯 개의 줄은 각각이 carriage return과 line feed로 이어진다.
- 메시지의 첫 줄은 요청행(request line)이라고 불린다.
- 해당 line은 다음 세 개의 필드를 가진다. 메소드(method) 필드, URL 필드, HTTP 버전 필드
- 메소드 필드 : GET, POST, HEAD, PUT, DELETE 등의 다양한 값을 가질 수 있다.
- URL 필드 : method가 GET일 때, 요청한 객체를 여기서 식별한다.
- HTTP 버전 필드 : 자신의 버전을 나타낸다.
- 이어지는 줄들은 헤더행(header line)이라고 불린다.
Host: www.someschool.edu: 객체가 위치한 호스트를 명시해준다.- 웹 프록시 캐시(Web proxy caches)가 헤더행을 필요로 한다. (TCP 연결이 이미 존재함에도 주소를 명시해야하는 이유)
Conenction: close: 지속적 연결을 하지 않는다는 의미. 서버가 요청된 객체를 보낸 뒤에 연결을 끊는다.User-agent:: 서버에 보낼 요청을 생성한 브라우저의 종류Accept-language:: 사용자가 객체를 받길 원하는 언어
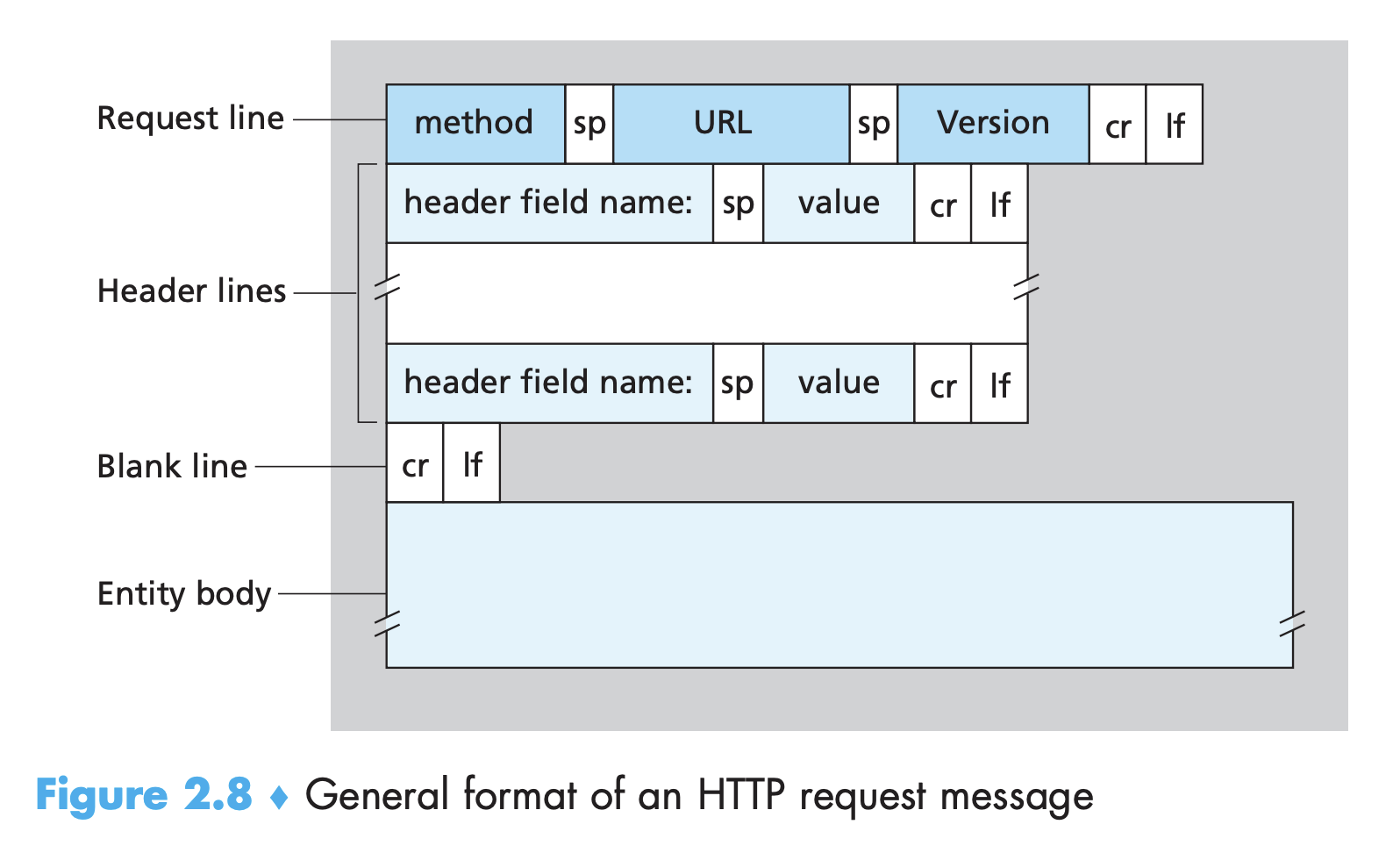
- 위의 엔티티 바디는 GET 메소드에서는 비워져 있지만, POST에서는 사용된다.
- 사용자가 양식을 채워넣는 작업을 할 때 주로 POST 메소드를 쓴다. 이렇게 되면 채워넣은 값이 엔티티 바디에 담긴다.
- 양식을 채워넣을 때 GET 메소드를 사용할 수도 있다. 이때는 URL에 데이터를 포함시킨다.
- 입력이 monkeys와 bananas라면, URL은
www.somesite.com/animalserach?monkeys&bananas가 된다.
- 입력이 monkeys와 bananas라면, URL은
- HEAD 메소드는 GET과 유사하다.
- 공통점 : 요청을 받았을 때 HTTP 메시지로 응답한다.
- 차이점 : 응답 메시지를 보낼 때, 요청받은 객체는 제외하고 보낸다.
- 주로 디버깅에 사용된다.
- PUT 메소드는 웹 퍼블리싱 도구와 결합해서 상요된다.
- 사용자가 객체를 특정 웹 서버의 특정 경로에 업로드하게 해준다.
- DELETE 메소드는 사용자나 애플리케이션이 웹 서버에서 객체를 삭제하도록 해준다.
HTTP Response Message
다음은 일반적인 HTTP 응답 메시지이다.
1
2
3
4
5
6
7
8
9
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data data data ...)
보다시피 1개의 상태행(status line), 6개의 헤더행과 엔티티 바디(entity body)를 가진다.
엔티티 바디는 요청받은 객체를 담고있다.
- 상태행
- 다음 세 개의 필드를 갖는다. 프로토콜 버전 필드, 상태 코드, 대응되는 상태 메시지
- 여기서는 서버가 HTTP/1.1을 사용하고 모든 것이 문제없다는 것을 나탄낸다.
- 헤더행
Connection: close: 서버가 메시지를 보낸 후 TCP 연결을 끊을 것이라는 것을 알려준다.Data:: HTTP 응답이 생성되고 보내진 일시Server:: 메시지가 Apache 웹 서버에 의해 생성됐다는 것을 나타낸다.Last-Modified:: 객체가 생성되거나 마지막으로 수정된 일시- object caching에 매우 중요한 정보이다.
Content-Length:: 보내진 객체의 바이트 길이Content-Type:: 엔티티 바디의 객체가 HTML 텍스트라는 것을 나타낸다.
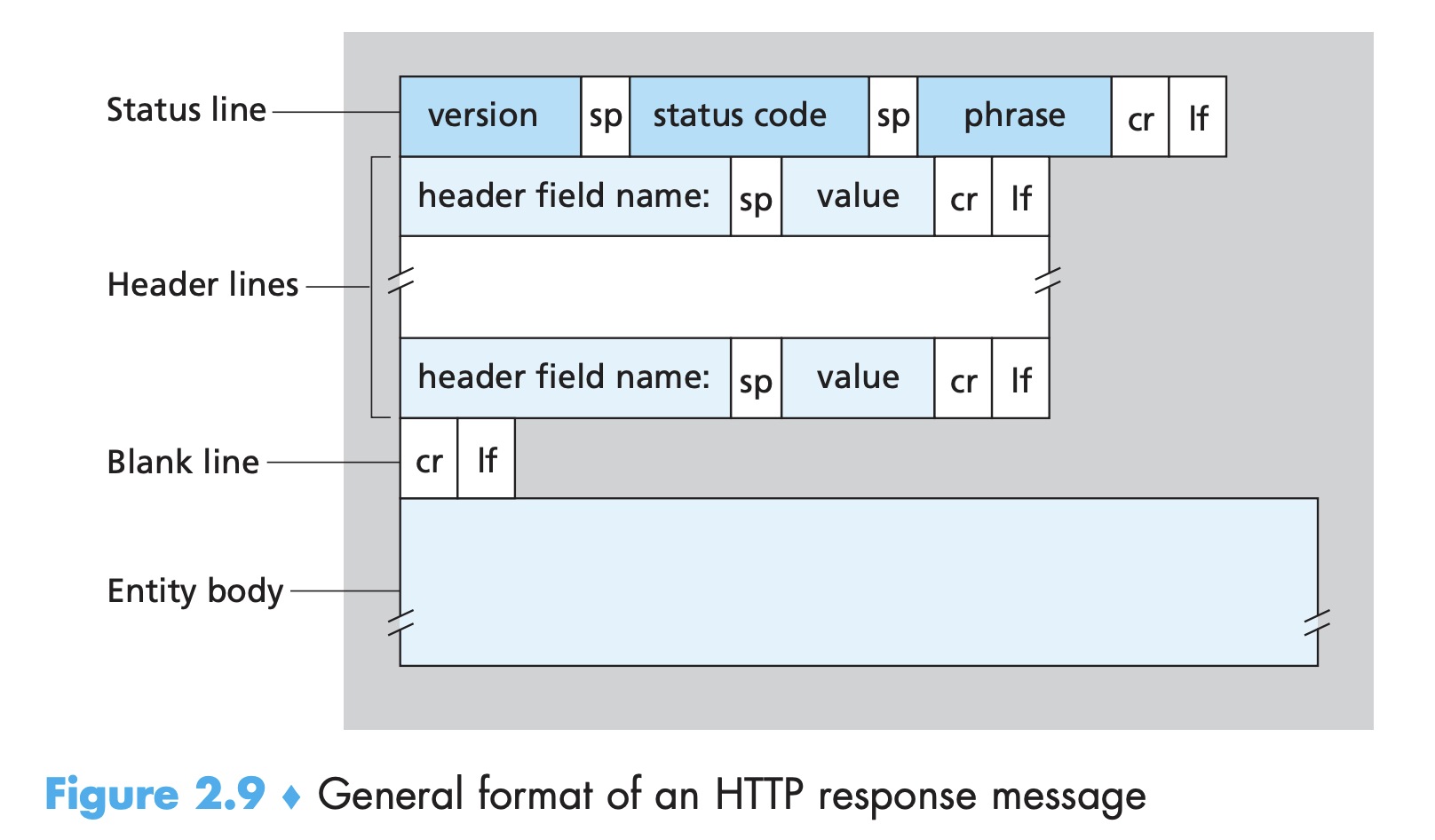
- 상태 코드
- 200 OK : 요청이 성공했고 정보가 응답으로 돌려보내졌다.
- 301 Moved Permanently : 요청된 객체가 영구적으로 옮겨졌다는 의미. 새로운 URL은
Location :에 명시되어 있다. - 400 Bad Request : 요청이 서버에서 이해할 수 없음을 총칭하는 오류 코드
- 404 Not Found : 요청된 문서가 서버에 존재하지 않는다.
- 505 HTTP Version Not Supported : 요청된 HTTP 프로토콜 버전이 서버에서 지원되지 않는다.
User-Server Interaction: Cookies
HTTP 서버는 클라이언트의 상태를 저장하지 않는다. : stateless
이로 인한 장점(높은 성능)도 있지만 사용자를 식별할 수 없다는 단점도 존재한다.
이러한 단점을 해결하기 위해 나온 것이 쿠키(cookie).
쿠키는 사용자를 추적할 수 있게 해준다.
- 쿠키 기술의 구성 요소
- HTTP 응답 메시지의 쿠키 헤더 행
- HTTP 요청 메시지의 쿠키 헤더 행
- 사용자의 종단 시스템에 보관되고 브라우저가 관리하는 쿠키 파일
- 웹 사이트의 백엔드 데이터베이스에 있는 쿠키 파일
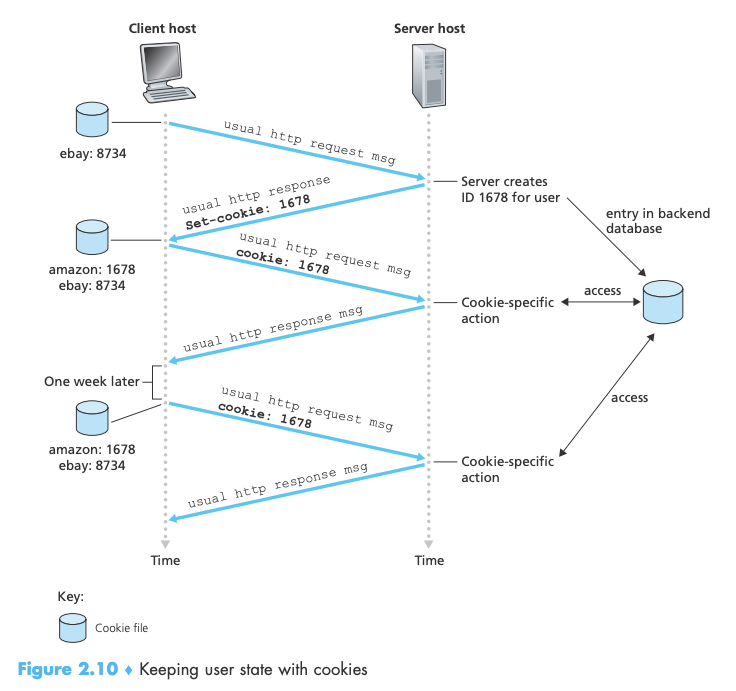
- 동작 방식 (그림 2.10) (내가 amazon.com에 처음 방문한 상황을 가정)
- 아마존 웹 서버가 내 요청을 받으면 고유한 번호를 생성하고 자신의 백엔드 데이터베이스에 해당 번호로 인덱싱된 엔트리를 만든다.
- 그 후
Set-cookie:헤더가 포함된 HTTP 응답을 내 브라우저로 보낸다.Set-cookie: 1678과 같이 고유 번호를 담고있다.
- 내 브라우저는 HTTP 응답 메시지를 받은 후
Set-cookie:헤더를 확인해서 관리중인 특수한 쿠키 파일에다가 한 줄 추가한다. - 이후에 특정 사이트를 방문하게 되면 쿠키 파일을 검색하여 고유 번호를 찾아서 HTTP 요청 메시지에 쿠키 헤더 행을 추가한다.
Cookie: 1678- 이렇게 되면 아마존은 내가 사이트에서 어떤 활동을 하는지를 추적할 수 있다.
Web Caching
웹 캐시(Web cache) 또는 프록시 서버(proxy server)는 원본(origin) 웹 서버를 대신하여 HTTP 요청을 만족하는 네트워크 독립체이다.
웹 캐시는 자신의 저장소에 최근에 요청된 객체의 사본을 저장해둔다.
- 동작 방식 (브라우저가 http://www.someschool.edu/campus.gif 라는 객체를 요청하는 상황을 가정)
- 브라우저는 웹 캐시와 TCP 연결을 설립하고 웹 캐시에 객체에 대한 HTTP 요청을 보낸다.
- 웹 캐시는 해당 사본이 로컬에 저장되어 있는지를 확인한다.
- 있다면 : HTTP 응답 메시지 안에 객체를 넣어서 클라이언트의 브라우저로 돌려보낸다.
- 없다면 : 웹 캐시는 원본 서버(www.someschool.edu)에 TCP 연결을 연다.
- 그 후 객체에 대한 HTTP 요청을 해당 연결을 통해 보낸다.
- 웹 캐시가 객체를 받으면 사본을 로컬 저장소에 저장해둔 뒤 HTTP 응답 메시지 안에 사본을 넣어서 클라이언트 브라우저에 보낸다.
- 사용 이유
- 클라이언트의 요청에 대한 응답 시간을 대폭 감소시켜준다.
- 기관(회사, 대학 등)의 인터넷 접속 링크에서 트래픽을 대폭 감소시켜준다.
Electronic Mail in the Internet
비동기 통신 매체 : 사람들이 메시지를 상대방과 같은 순간이 아니라, 자신이 원할 때에 보낸다.
- 인터넷 메일 시스템의 주요 구성 요소 (그림 2.14)
- user agents
- mail servers
- Simple Mail Transfer Protocol (SMTP)
- 인터넷 이메일의 기본 애플리케이션 계층 프로토콜
- 송신자의 메일 서버에서 수신자의 메일 서버로 TCP의 reliable data transfer를 사용한다.
- 클라이언트측과 서버측으로 구성된다.
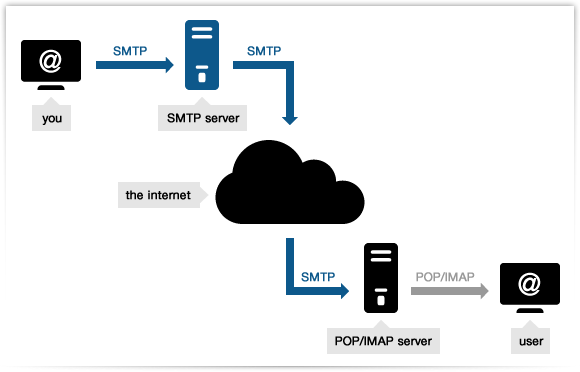
SMTP
- 메일 메시지의 바디를 단순한 7비트 ASCII로 제한한다.
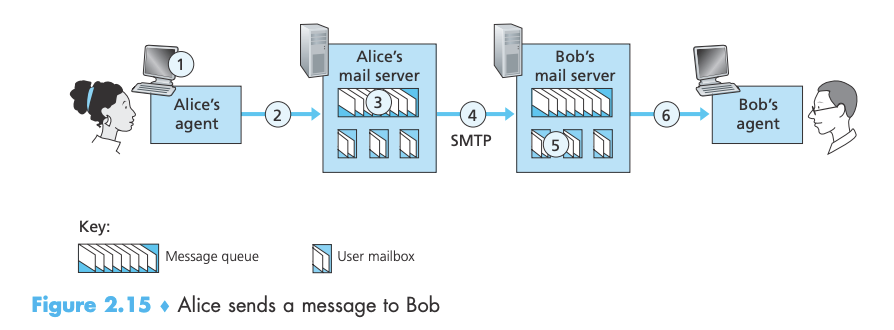
- 동작 과정 (그림 2.15)(좌측의 Alice가 우측의 Bob에게 단순한 ASCII 메시지를 전송하는 상황을 가정)
- Alice가 자신의 유저 에이전트를 불러서, Bob의 이메일 주소를 주고, 메시지를 구성한 뒤, 메시지를 보내라고 시킨다.
- Alice의 유저 에이전트는 Alice의 메일 서버에 메시지를 보낸다. 메시지는 메시지 큐에 놓여진다.
- Alice의 메일 서버에서 동작하는 클라이언트 측 SMTP는 메시지 큐에 있는 메시지를 발견한다. 그 후 밥의 메일 서버에서 동작하는 SMTP 서버와 TCP 연결을 생성한다.
- 초기 SMTP handshaking 이후에 SMTP 클라이언트가 Alice의 메시지를 TCP 연결을 통해 보낸다.
- Bob의 메일 서버에서, 서버 측 SMTP가 메시지를 수신한다. 밥의 메일 서버는 메시지를 밥의 우편함에 넣는다.
- Bob이 자신의 유저 에이전트를 불러서 메시지를 읽도록 한다.
SMTP vs HTTP
- 공통점
- 두 프로토콜 모두 호스트 간의 파일 전송에 사용된다.
- HTTP : 웹 서버에서 웹 클라이언트로 파일 전송
- SMTP : 한 쪽의 메일 서버에서 다른 쪽의 메일 서버로 파일 전송
- 지속적 HTTP와 SMTP 모두 지속적인 연결을 형성한다.
- 두 프로토콜 모두 호스트 간의 파일 전송에 사용된다.
- 차이점
- 프로토콜의 종류
- SMTP : 주로 push 프로토콜—보내는 메일 서버가 받는 메일 서버로 파일을 push한다.
- HTTP : 주로 pull 프로토콜—한 사람이 웹 서버에 정보를 로드하면 사용자가 HTTP를 통해 원할 때 정보를 pull한다.
- 메시지 형식의 제약
- SMTP : 각 메시지가 7비트의 ASCII 형식을 갖춰야 한다. 아니라면 해당 형식으로 변환해야 한다.
- HTTP : 형식에 제약이 없다.
- 글과 이미지가 포함된 문서가 처리되는 방식
- HTTP : 각 객체를 자신의 HTTP 응답 메시지 안에 넣는다.
- SMTP : 모든 메시지의 객체를 한 메시지 안에 넣는다.
- 프로토콜의 종류
Mail Message Formats
1
2
3
From: alice@crepes.fr
To: bob@hamburger.edu
Subject: Searching for the meaning of life.
일반적인 메시지 헤더는 위와 같다. From과 To는 필수적이고 Subject나 기타 헤더는 선택사항이다.
이 뒤에 공백 줄이 나오고 그 뒤로 메시지 바디(ASCII 형식으로)가 나온다.
Mail Access Protocols
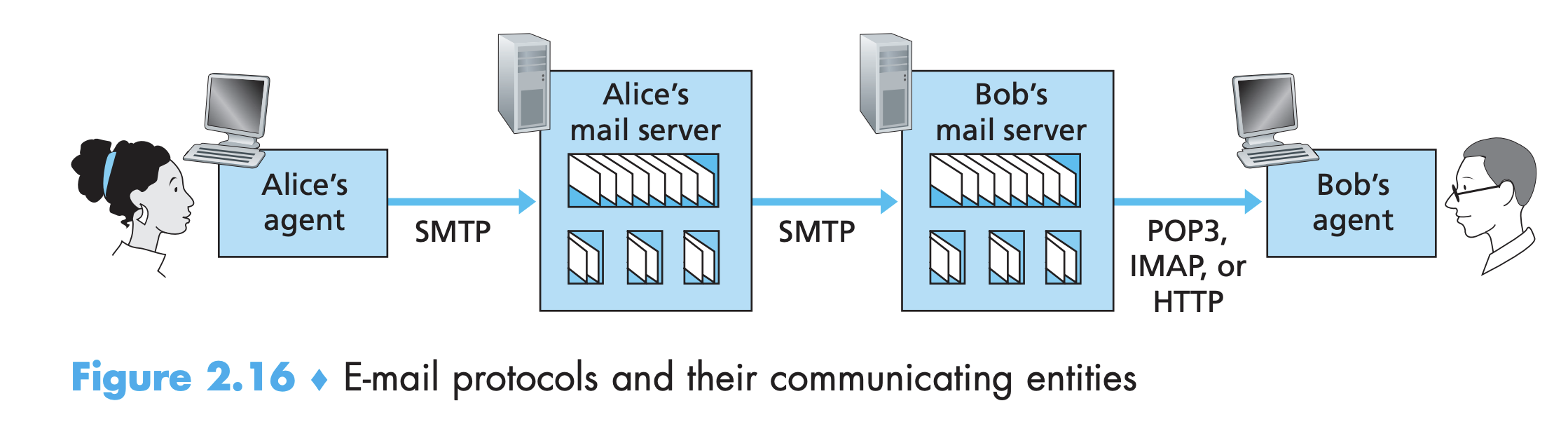
앨리스가 밥에게 메일을 보내는 상황을 다시 가정해보자. (그림 2.16)
- 동작 과정
- 앨리스의 메일 서버가 밥의 메일 서버로 메시지를 보내면 메시지는 밥의 메일함에 놓여진다.
- 이때, 1990년대까지는, 밥이 서버 호스트에 로그인해서 호스트에서 동작하는 메일 reader를 실행하도록 했다.
- 하지만 오늘날은 메일 접속에 클라이언트-서버 구조를 사용한다. 이때는 사용자의 종단 시스템에서 실행되는 클라이언트(사무실 PC, 스마트폰 등)로 이메일을 읽는다.
- 사용자는 자신의 로컬 PC에서 유저 에이전트를 실행하고 공유되는 메일 서버(항상 켜져있음)에 있는 메일함에 접속한다.
- 아래 그림과 같이 앨리스의 유저 에이전트가 SMTP를 통해 자신의 메일 서버로 메시지를 push한다.
- 앨리스의 메일 서버가 SMTP를 사용해서 메시지를 밥의 메일 서버로 넘겨준다.
- 특수한 메일 접속 프로토콜을 통해 밥의 메일 서버에서 밥의 로컬 PC로 메시지를 전송한다.
- 이러한 역할을 하는 프로토콜로는 Post Officde Protocol-Version 3 (POP3), Internet Mail Access Protocol(IMAP), HTTP 등이 있다.
- 앨리스의 메일 서버가 밥의 메일 서버로 메시지를 보내면 메시지는 밥의 메일함에 놓여진다.
POP3
매우 단순한 메일 접근 프로토콜이다.
유저 에이전트가 포트 110번에 메일 서버로의 TCP 연결을 연 경우에 POP3가 시작된다.
TCP 연결이 개설되면 다음 세 과정이 진행된다. authorization, transaction, update
- authorization
- 유저 에이전트는 인증된 사용자에게 유저명과 비밀번호를 보낸다.
user <username>,pass <password>명령어가 있다.1 2 3 4 5 6
telnet mailServer 110 +OK POP3 server ready user bob +OK pass hungry +OK user successfully logged on
- transaction
- 유저 에이전트는 메시지를 검색한다.
- 이 과정에서 삭제 표시를 할 수도 있고, 삭제 표시를 없앨 수도 있고 메일 통계를 얻을 수도 있다.
list,retr,dele,quit명령어가 있다.
- update
- 클라이언트가 quit 명령을 실행한 이후에 일어난다.
- POP3 세션을 종료한다.
- 이 시점에 메일 서버는 삭제 표시가 되어있던 메시지들을 삭제한다.
POP3 과정동안 유저 에이전트는 명령을 실행하고, 서버는 각가의 명령에 대해 응답한다.
- 응답의 종류
+OK: 이전 명령에 문제가 없다는 의미-ERR: 이전 명령에 문제가 있다는 의미
IMAP
POP3를 사용하면 메시지를 로컬 기기에 내려받아서 자신의 메일 폴더에 메시지를 위치시킨다.
이렇게 되면 자주 이동하는 사용자의 경우 제약이 생긴다. (폴더를 원격 서버에 위치시켜야 하는 필요성)
IMAP은 POP3보다 많은 기능을 가진 프로토콜로, 더욱 복잡한 형태를 지닌다.
- IMAP 서버는 각 메시지를 폴더와 연결시킨다.
- 메시지가 서버에 처음 도착하면 수신자의 인박스 폴더와 연결된다.
- 수신자는 메시지를 사용자가 새롭게 생성한 폴더에 옮기거나, 읽거나, 삭제할 수 있다.
- IMAP에는 유저 에이전트가 메시지의 구성 요소를 얻을 수 있도록 하는 명령이 있다.
- 유저 에이전트는 메시지 헤더 하나만 얻을 수도 있고, 여러 MME 메시지의 한 부분만 얻을 수도 있다.
웹 기반 이메일
요즘에는 많은 사용자가 웹 브라우저를 통해 이메일에 접근한다.
- 수신자
- 내가 나의 메일함에 접근하려고 한다면, 이메일 메시지가 HTTP 프로토콜을 통해 메일 서버에서 브라우저로 보내진다.
- 송신자
- 내가 메일을 보내려고 한다면, 브라우저에서 메일 서버로 HTTP를 통해 이메일 메시지가 보내진다.
DNS-The Internet’s Directory Service
- 인터넷 호스트를 식별하는 수단
- 호스트명
- www.google.com, www.facebook.com 등
- 연상 기호화되어 있어서 사람에게 편하다.
- 임의의 길이의 알파벳&숫자의 조합으로 구성됐기 때문에 라우터가 처리하기 어렵다.
- IP 주소
- 121.7.106.83 과 같이 4바이트로 구성되어 있다.
- 왼쪽에서 오른쪽으로 읽어가면서 인터넷 상에 속한 위치를 알아갈 수 있다.(계층적)
- 호스트명
Services Provided by DNS
위의 두 가지 식별자(호스트명, IP 주소) 중 사람들은 읽기 편한 호스트명을, 라우터는 계층적으로 구성된 IP 주소를 더 선호한다.
Domain Name System (DNS)가 하는 역할은 호스트명을 IP 주소로 번역해주는 것이다.
- DNS
- DNS 서버의 계층 구조에서 구현되는 분산 데이터베이스
- 호스트가 분산 데이터베이스를 호스트가 분산 데이터베이스를 쿼리할 수 있도록 하는 애플리케이션 계층 프로토콜
- 쿼리(query) : 데이터베이스에게 특정 데이터를 보여달라는 클라이언트의 요청
- DNS 프로토콜은 UDP를 통해 동작하고 53번 포트를 사용한다.
- 동작 과정 (www.someschool.edu/index.html을 요청하는 상황)
- 동일한 사용자 머신이 DNS 애플리케이션의 클라이언트 측을 실행한다.
- 브라우저가 URL에서 호스트명인 www.someschool.edu를 추출하여 DNS 애플리케이션의 클라이언트 측에 전달한다.
- DNS 클라이언트가 호스트명이 포함된 쿼리를 DNS 서버로 보낸다.
- DNS 클라이언트가 호스트명에 대한 IP 주소가 포함된 답변을 받는다.
- 브라우저가 IP 주소를 받으면 HTTP 서버 프로세스로 TCP 연결을 시작할 수 있다.
이로 인해 딜레이가 발생할 수 있지만 보통은 인근 DNS 서버에 IP 주소가 저장되어 있다.
- DNS의 추가 기능
- 호스트 별칭(Host aliasing)
- 복잡한 호스트명을 가진 호스트는 하나 이상의 별칭(alias)을 가질 수 있다.
- relay1.west-coast.enterprise.com 이라는 호스트명이 있다고 할 때 이걸 표준 호스트명(canonical hostname)이라고 하고 enterprise.com, www.enterprise.com을 호스트명 별칭이라고 한다.
- 제공된 별칭에 대한 표준 호스트명을 얻기 위해 DNS를 호출한다.
- 메일 서버 별칭(Mail server aliasing)
- yahoo.com과 같은 호스트명 별칭을 relay1.west-coast.yahoo.com과 같은 표준 호스트명으로 변환하기 위해 호출한다.
- 부하 분산(Load distribution)
- 복제된 여러 서버에 부하를 분산한다.
- 이렇게 복제된 웹 서버의 IP 주소의 집합은 하나의 표준 호스트명과 연결된다.
- 이러한 정보는 DNS 데이터베이스에 보관된다.
- 호스트 별칭(Host aliasing)
Overview of How DNS Works
DNS를 가장 단순하게 구현하는 방법은 중앙화를 하는 것이다.
이렇게 되면 하나의 DNS에 클라이언트들의 모든 쿼리를 보내면 된다. 하지만 이러한 구조에는 다음과 같은 문제가 있다.
- A single point of failure
- DNS 서버가 망가지면 전체 인터넷도 망가지게 된다.
- Traffic volume
- 한 DNS 서버가 모든 DNS 쿼리를 다뤄야한다.
- Distant centralized database
- 한 DNS 서버는 쿼리를 보내는 모든 클라이언트들과 가까이 있을 수는 없다.
- Maintenance
- 한 DNS 서버가 모든 인터넷 호스트에 대한 기록을 가지고 있어야 한다.
A Distributed, Hierarchical Database
스케일 문제 때문에 DNS는 많은 서버를 계층적으로 구성하고 전세계에 분산시켜 사용한다.
호스트에 대한 매핑은 DNS 서버들에 분산되어있다.
- DNS 서버 클래스의 종류
- root DNS 서버
- 최상위 도메인(top-level domain, TLD) DNS 서버
- authoritative DNS 서버
- 동작 과정 (DNS 클라이언트가 호스트명이 www.amazon.com인 호스트의 IP 주소를 찾는 상황) (그림 2.17)
- 클라이언트가 root 서버 중 하나에 접근해서 최상위 도메인인 com과 맞는 TLD 서버의 IP 주소들을 받는다.
- 클라이언트는 해당 TLD 서버들 중 하나에 접근해서 amazon.com과 맞는 authoritative 서버의 IP 주소를 받는다.
- 클라이언트는 해당 authoritative 서버에 접근해서 호스트명인 www.amazon.com에 대한 IP 주소를 받는다.
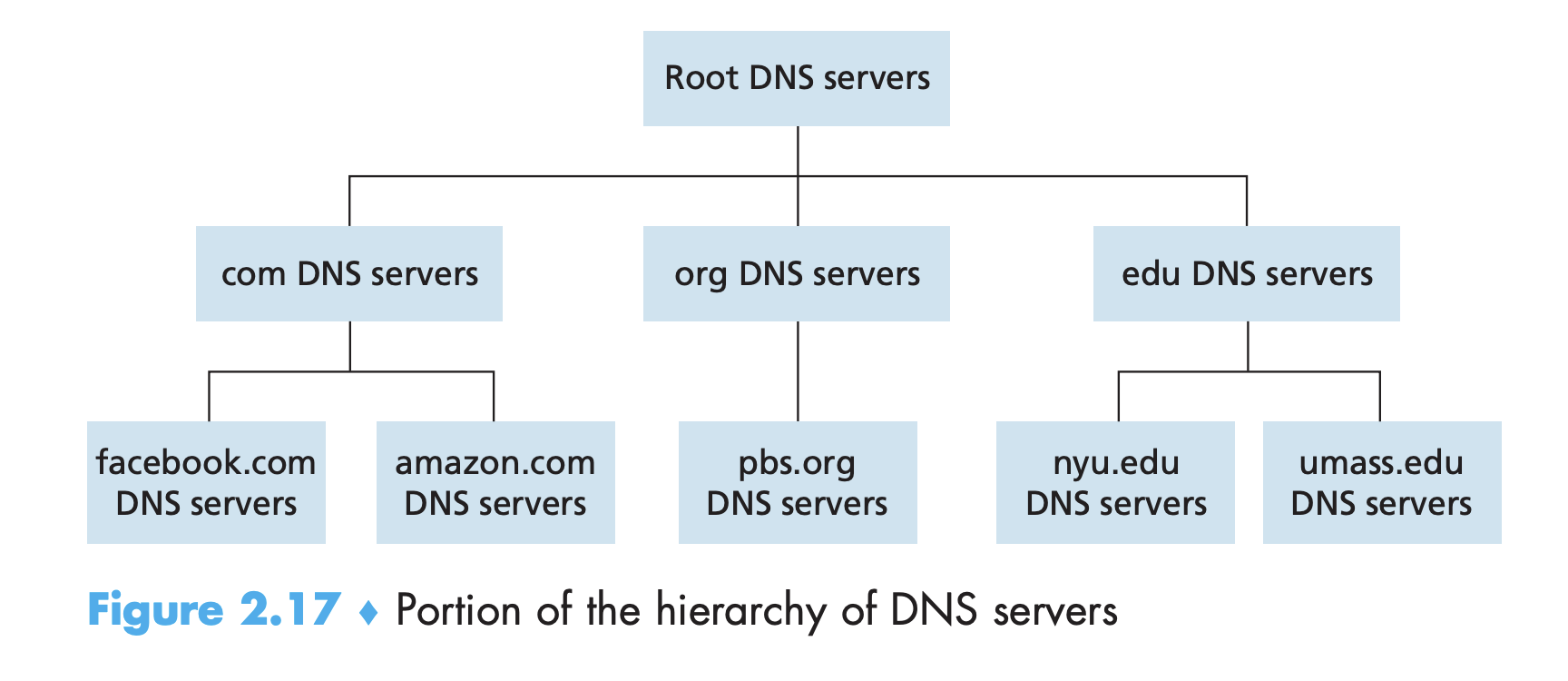
- Root DNS 서버
- 전세계에 약 400개가 넘는 루트 서버가 흩어져있다.
- TLD 서버의 IP 주소를 제공하는 역할을 한다.
- 최상위 도메인(Top-level domain, TLD) DNS 서버
- 각각의 최상위 도메인(com, org, net, edu 등)에 대해 TLD 서버가 존재한다.
- 이들은 authoritative DNS 서버의 IP 주소를 제공하는 역할을 한다.
- Authoritative DNS 서버
- 인터넷 상의 호스트들의 DNS 레코드를 보관한다.
- DNS 레코드 : 인터넷 상의 공개적으로 접근 가능한 호스트들이 갖는 호스트명과 IP 주소의 매핑 정보
- 인터넷 상의 호스트들의 DNS 레코드를 보관한다.
DNS 캐싱 (DNS Caching)
DNS는 성능의 지연을 개선하고 인터넷 상에서 튕겨져 나오는 DNS 메시지를 줄이기 위해 DNS 캐싱을 사용한다.
DNS 서버가 DNS 응답을 받으면, 이 안에 들어있는 매핑을 로컬 메모리에 잠시 저장한다.
이렇게 호스트명/IP 주소 쌍의 정보가 DNS 서버에 cache된 상태에서 동일한 정보를 요청받으면, 권한이 없더라도 원하는 IP 주소를 제공할 수 있다.
DNS Records and Messages
DNS 분산 데이터베이스를 같이 사용하는 DNS 서버들은 자원 레코드(resource record, RR)를 저장한다.
RR에는 호스트명에서 IP 주소로의 매핑을 포함한 다양한 정보가 있다.
각각의 DNS 응답 메시지가 하나 이상의 RR을 가진다.
RR의 형식
(Name, Value, Type, TTL)
DNS 메시지
- DNS 메시지 종류
- DNS 쿼리
- 응답 메시지
DNS 메시지 형식
![Untitled]()

{kind=link}
Peer-to-Peer File Distribution
여태까지는 항상 켜진 서버에 상당히 의존하는 클라이언트-서버 아키텍처들만 살펴봤다. 반면 P2P 아키텍처의 경우 상시 서버 대신 호스트 쌍끼리 직접 통신한다.
이 장에서는 하나의 서버에서 가져온 대용량 파일을 다수의 호스트(peer)에게 퍼뜨리는 P2P 애플리케이션을 살펴볼 것이다.
P2P 파일 배포에서 각 피어는 자신이 수신한 파일을 일부분을 다른 피어에게 재배포할 수 있다.
P2P 아키텍처의 확장성
- 각종 표기법
- $u_s$ : 서버의 접속 링크의 업로드 속도
- $u_i$ : i 번째 피어의 접속 링크의 업로드 속도
- d_i : i 번째 피어의 접속 링크의 다운로드 속도
- $F$ : 분산될 파일의 크기(비트로)
- $N$ : 해당 파일의 사본을 얻길 원하는 피어의 개수
- D : 배포(distribution) 시간. 파일의 사본을 N대의 피어 모두가 받는데 걸리는 시간
- $u_s$ : 서버의 접속 링크의 업로드 속도
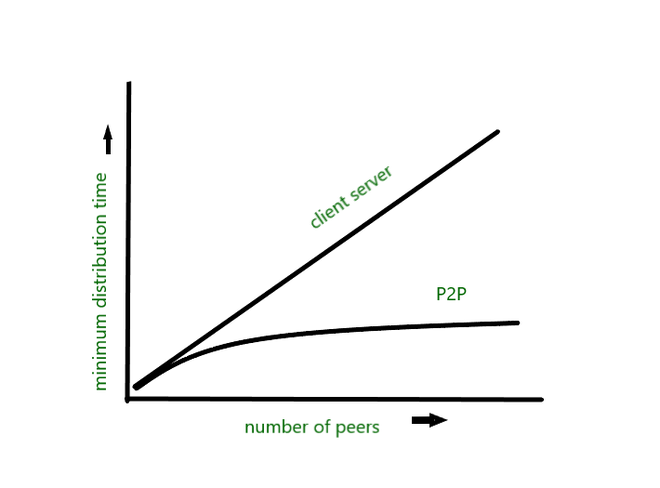
클라이언트-서버 아키텍처의 경우, 피어의 수가 증가함에 따라 배포 시간이 직선 형태로 제한 없이 증가한다. 반면 P2P 아키텍처의 경우, 최소 배포 시간이 항상 클라이언트-서버 아키텍처보다 적게 걸린다.
또한 P2P 아키텍처를 사용하는 애플리케이션은 자체 확장이 가능하다. 이는 피어들이 비트의 재배포에도 관여하기 때문이다.
BitTorrent
BitTorrent는 파일 배포에서 인기 있는 P2P 프로토콜이다.
토렌트(torrent) : 특정 파일의 배포에 관여하는 모든 피어들의 집합
- 동작 방식
- 토렌트의 피어들은 다른 피어로부터 동일한 크기의 덩어리(chunk)(주로 256kB)를 다운로드한다.
- 피어가 처음 토렌트에 참여할 때는 덩어리가 없다. 시간이 흐름에 따라 해당 피어는 점점 많은 덩어리들을 축적해나간다.
- 피어는 덩어리들을 다운로드하는 동시에 덩어리들의 업로드도 한다.
- 피어가 파일 전체를 갖게되면 토렌트를 떠나버리거나 다른 피어들에게 업로드해주기 위해 토렌트에 남을 수도 있다.
- 파일을 일부분만 받은 피어도 토렌트를 언제든 떠났다가 나중에 다시 들어올 수도 있다.