이전 글에서 이어지는 글입니다. 이 글은 프로젝트에서의 구체적인 Spring Batch Job 구현 내용과 파이프라인 안정화 과정에서 마주했던 이슈를 다룹니다.
Spring Batch Job 구현
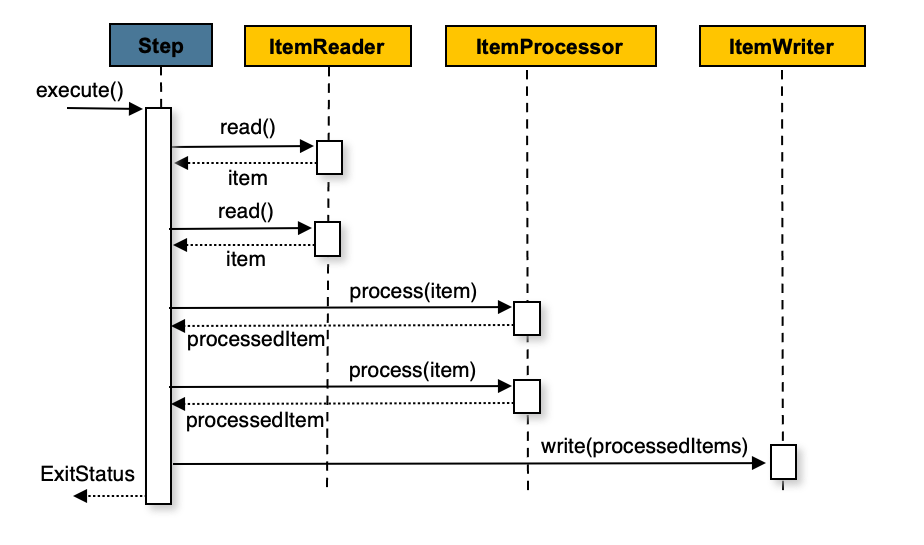 Chunk 기반 처리
Chunk 기반 처리
Spring Batch는 대용량 데이터를 처리할 때, 지정된 개수(Chunk)만큼 데이터를 메모리에 읽어 한 번에 처리하고 저장하는 Chunk 기반 처리 모델을 사용한다. 이 모델은 ItemReader, ItemProcessor, ItemWriter라는 세 가지 컴포넌트로 구성되며, 각 컴포넌트의 역할을 명확히 분리하여 구현했다.
kamisDailyPriceSyncJob: 일일 가격 데이터 수집
매주 화~토요일 오전 3시에 전날의 지역별 가격 데이터를 수집하여 daily_regional_price 테이블에 저장하는 Job이다.
ItemReader(KamisDailyPriceApiReader):read()메서드가 처음 호출될 때, 사전에 정의된 모든 지역과 상품 부류 코드 조합에 대해 KAMIS API를 호출하여 모든 가격 데이터를 메모리에 로드한다.- 이후
read()가 호출될 때마다 메모리에 로드된 데이터를 하나씩 반환한다.
ItemProcessor(KamisDailyPriceProcessor):- API 응답 DTO를 DB에 저장하기 위한
DailyRegionalPrice엔티티로 변환한다. - 매번 DB를 조회하는 오버헤드를 줄이기 위해,
product와region마스터 데이터를lazy초기화를 통해 메모리에 캐싱하고, 이를 활용하여 엔티티를 조립한다.
- API 응답 DTO를 DB에 저장하기 위한
ItemWriter(JpaItemWriter):- Spring Batch가 기본으로 제공하는
JpaItemWriter를 사용했다. Processor로부터 전달받은 엔티티 목록을 Chunk 단위로 묶어 효율적인 Bulk Insert를 수행한다.
- Spring Batch가 기본으로 제공하는
1
2
3
4
5
6
7
8
9
10
// KamisDailyPriceBatchConfiguration.kt
@Bean
fun kamisDailyPriceSyncStep(): Step {
return StepBuilder(STEP_NAME, jobRepository)
.chunk<KamisDailyPriceApiData, DailyRegionalPrice>(CHUNK_SIZE, transactionManager)
.reader(kamisDailyPriceApiReader(null))
.processor(kamisDailyPriceProcessor(null))
.writer(kamisDailyPriceJpaWriter())
.build()
}
kamisAnnualPriceSyncJob: 연평균 가격 데이터 갱신
매주 일요일 오전 4시에 상품별 당해 전국 평균 가격을 annual_national_price 테이블에 갱신하는 Job이다.
ItemReader(JpaPagingItemReader):- 일일 가격 Job과 달리, 이 Job은 DB에 저장된 각 상품별로 API를 호출해야 한다.
- 따라서
JpaPagingItemReader를 사용하여Product테이블의 데이터를 페이징 기반으로 안전하게 조회했다.
ItemProcessor(KamisAnnualPriceProcessor):- Reader로부터 전달받은
Product엔티티 정보를 기반으로 ‘연도별 가격 API’를 호출한다. - API 응답(JSON)을 파싱하여
AnnualNationalPrice엔티티 리스트로 변환한다.
- Reader로부터 전달받은
ItemWriter(커스텀KamisAnnualPriceJpaItemWriter):- 이 Job은 데이터가 이미 존재하면
UPDATE, 없다면INSERT를 수행(Upsert)해야 했다. - 이를 위해 커스텀
ItemWriter를 구현했다. Writer는 전달받은 엔티티에 대해 DB에 데이터가 존재하는지 먼저 확인하고, 존재 여부에 따라 엔티티의 상태를 변경하거나(UPDATE), 그대로 저장(INSERT)하는 로직을 수행한다.
- 이 Job은 데이터가 이미 존재하면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// KamisAnnualPriceJpaItemWriter.kt
class KamisAnnualPriceJpaItemWriter(...) : ItemWriter<List<AnnualNationalPrice>> {
override fun write(chunk: Chunk<out List<AnnualNationalPrice>>) {
val flattenedList = chunk.items.flatten()
// ...
for (item in flattenedList) {
val existingPrice = annualNationalPriceRepository.findByProductIdAndSurveyYearAndMarketType(...)
if (existingPrice != null) {
existingPrice.updatePrice(item.price) // UPDATE
itemsToSave.add(existingPrice)
} else {
itemsToSave.add(item) // INSERT
}
}
annualNationalPriceRepository.saveAll(itemsToSave)
}
}
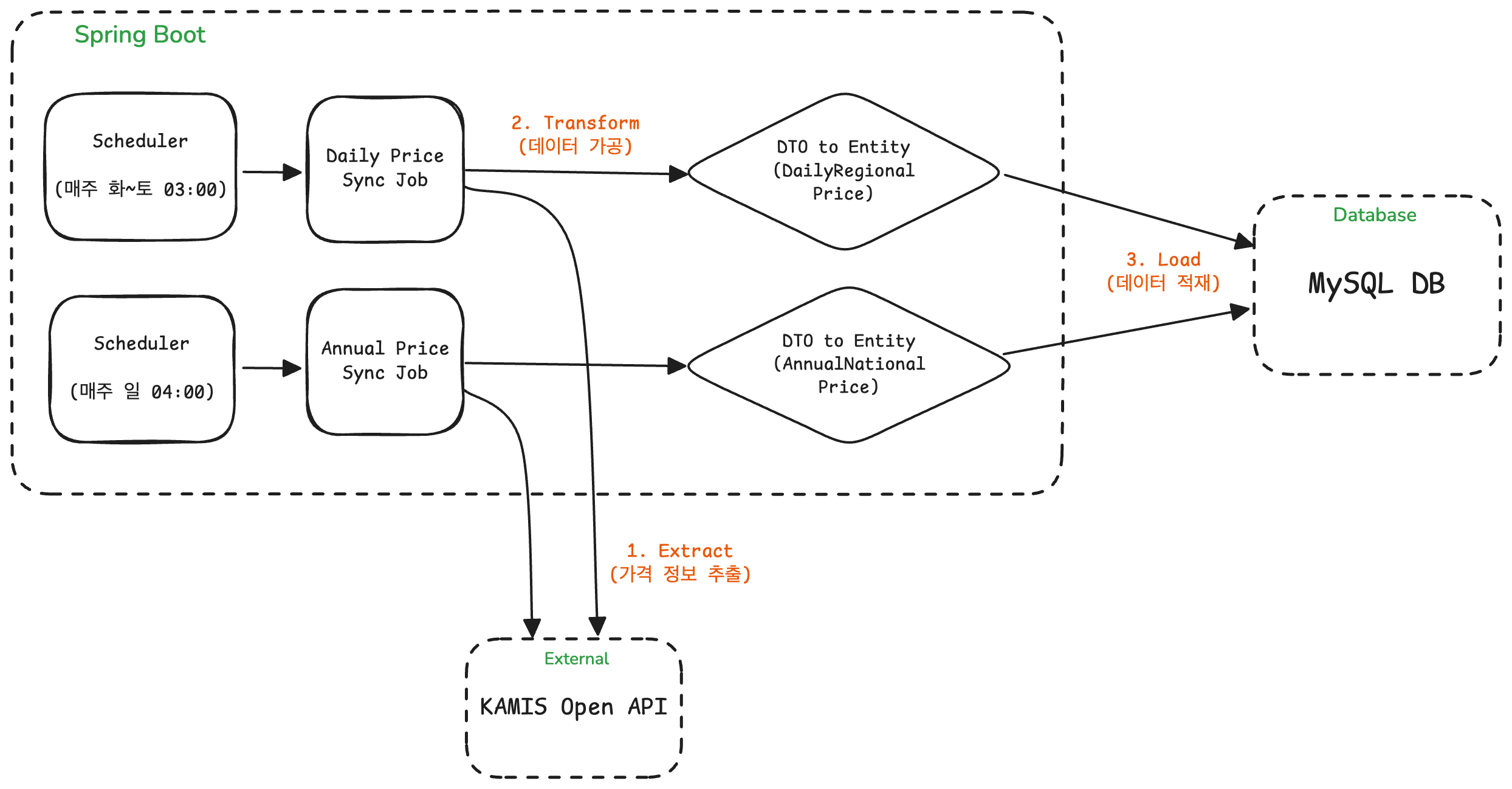
최종 ETL 파이프라인
최종적인 ETL 파이프라인은 다음과 같다.
테스트용 API 구현
배치 Job을 개발하고 테스트하는 과정에서 스케줄링된 시간까지 기다리는 것은 매우 비효율적이다. 이를 해결하기 위해 @Profile 어노테이션을 활용하여 local과 dev 환경에서만 활성화되는 배치 수동 실행 API를 구현했다.
1
2
3
4
5
6
7
8
9
10
11
// BatchJobController.kt
@RestController
@RequestMapping("/api/v1/batch")
@Profile("local", "dev")
class BatchJobController(...) {
@PostMapping("/run/{jobName}")
fun runBatchJob(@PathVariable jobName: String): ResponseEntity<String> {
// ... JobLauncher를 사용하여 Job 실행 ...
}
}
주요 이슈
외부 API 호출 시 간헐적 네트워크 오류 발생
현상
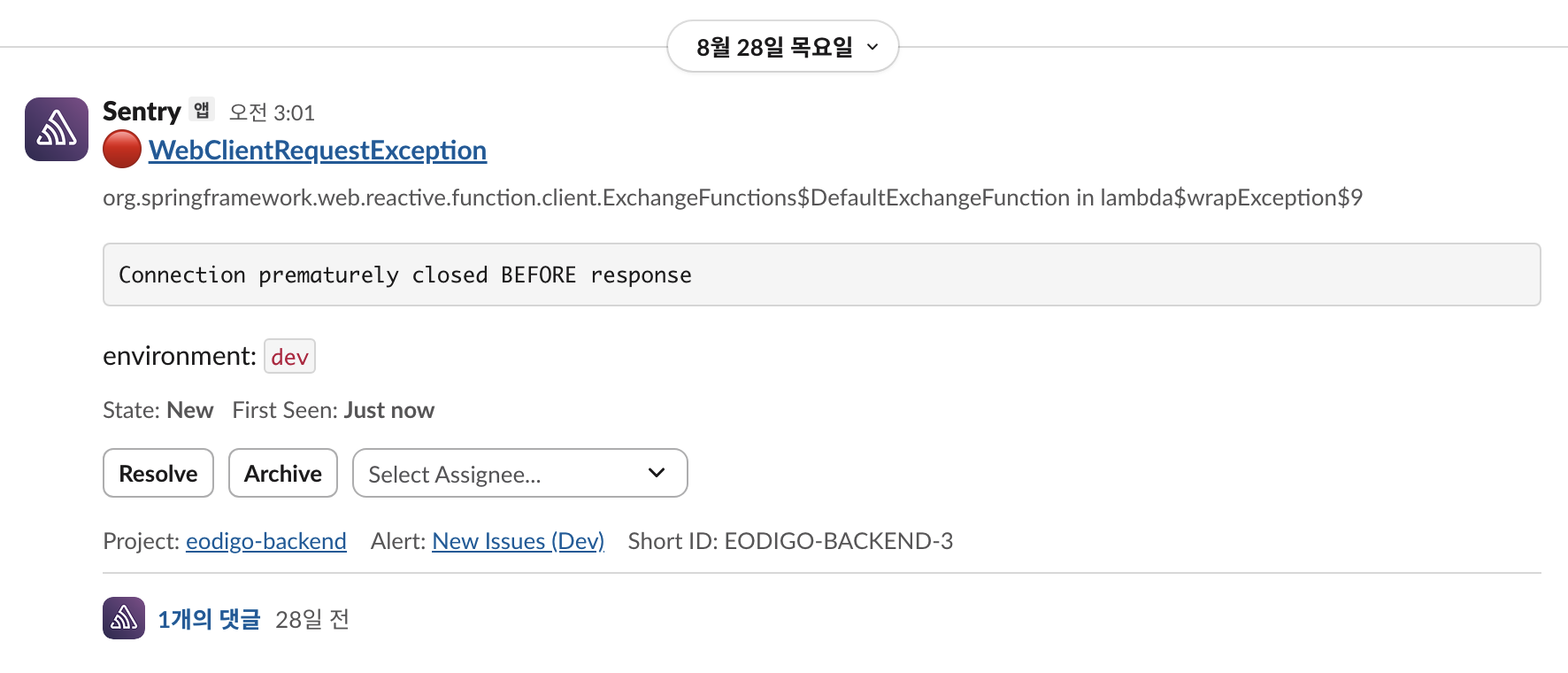
![slack sentry notification]() Slack Sentry 알림
Slack Sentry 알림사전에 구축한 Sentry에서 보낸 Slack 알림을 통해 배치 작업이 실패했음을 인지하였다.
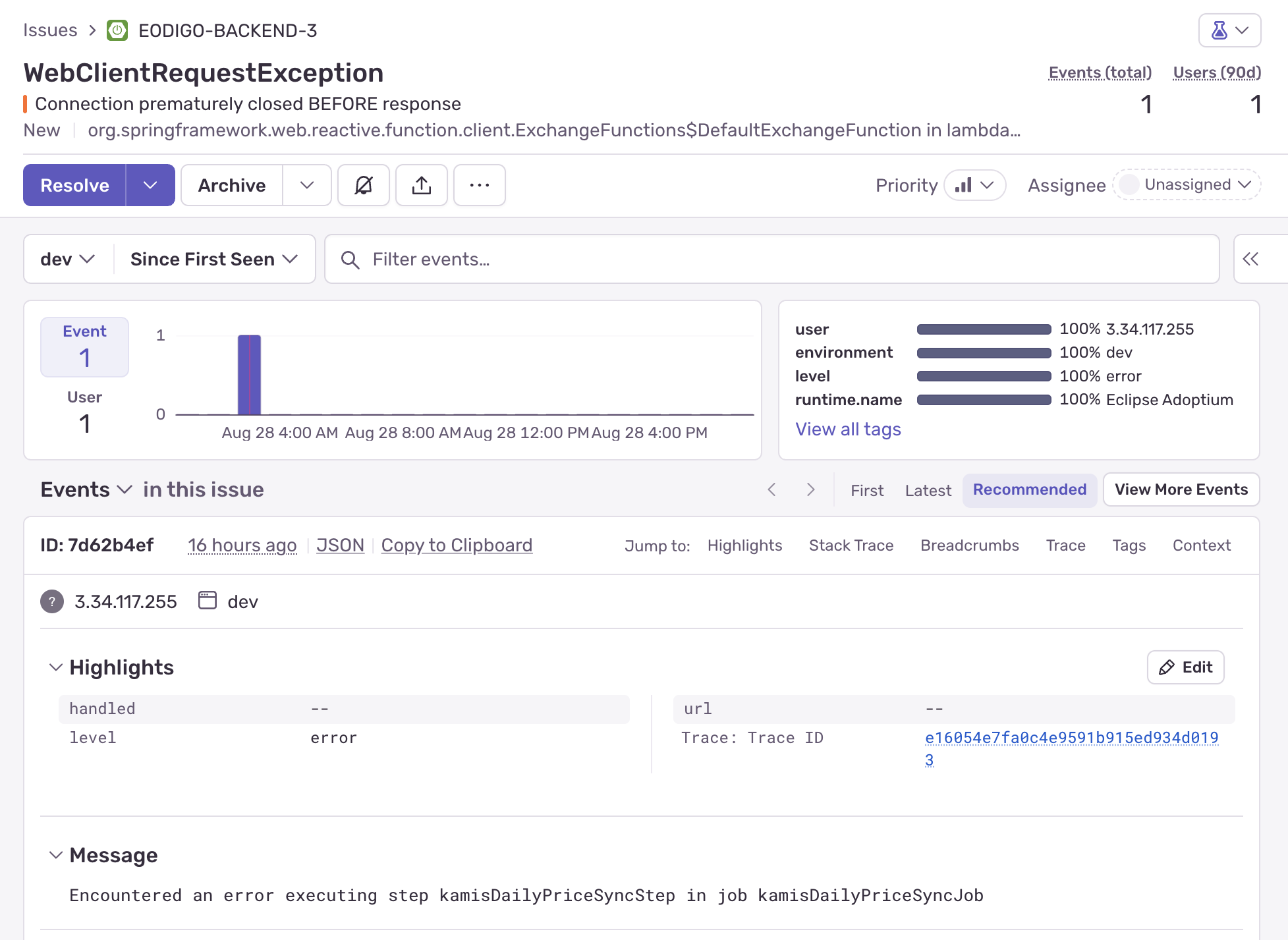
![sentry error]() Sentry 대시보드에 기록된 에러
Sentry 대시보드에 기록된 에러이후 Sentry 대시보드에 접속하여 세부 에러 정보를 확인했다. 새벽 3시에 실행된 kamisDailyPriceSyncJob(일일 가격 배치)이 실패한 것이었다.
1
WebClientRequestException: Connection prematurely closed BEFORE response
![batch_log 1]() BATCH_JOB_EXECUTION (1)
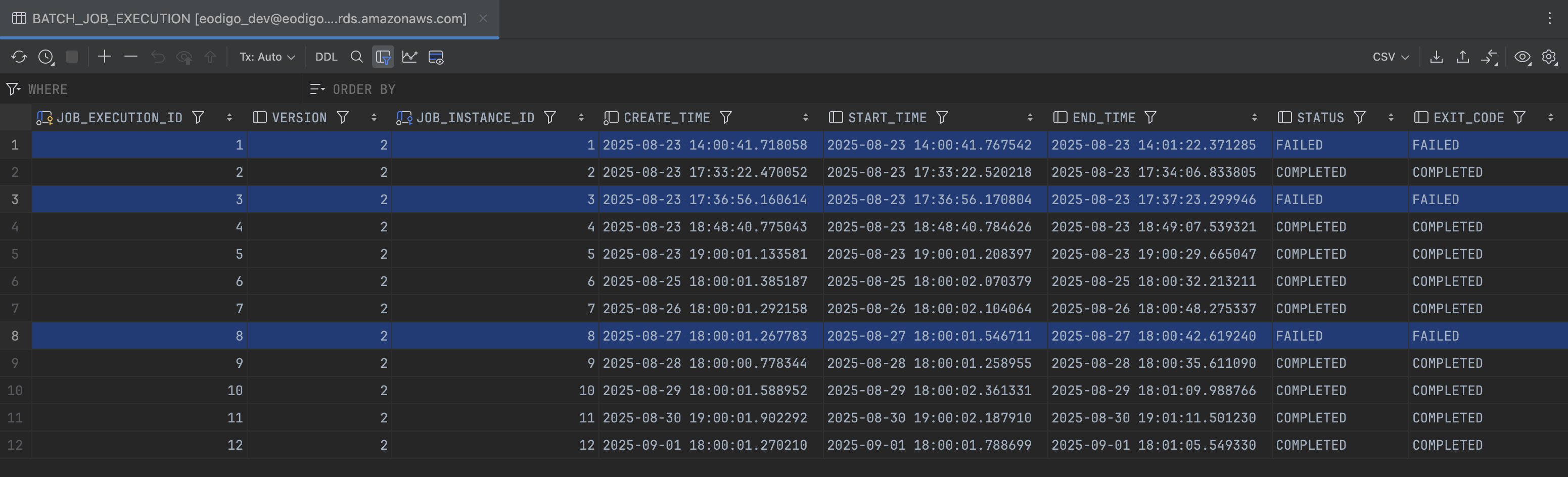
BATCH_JOB_EXECUTION (1)Sentry 구축 이전에도 유사한 에러가 발생했는지를 확인하기 위해
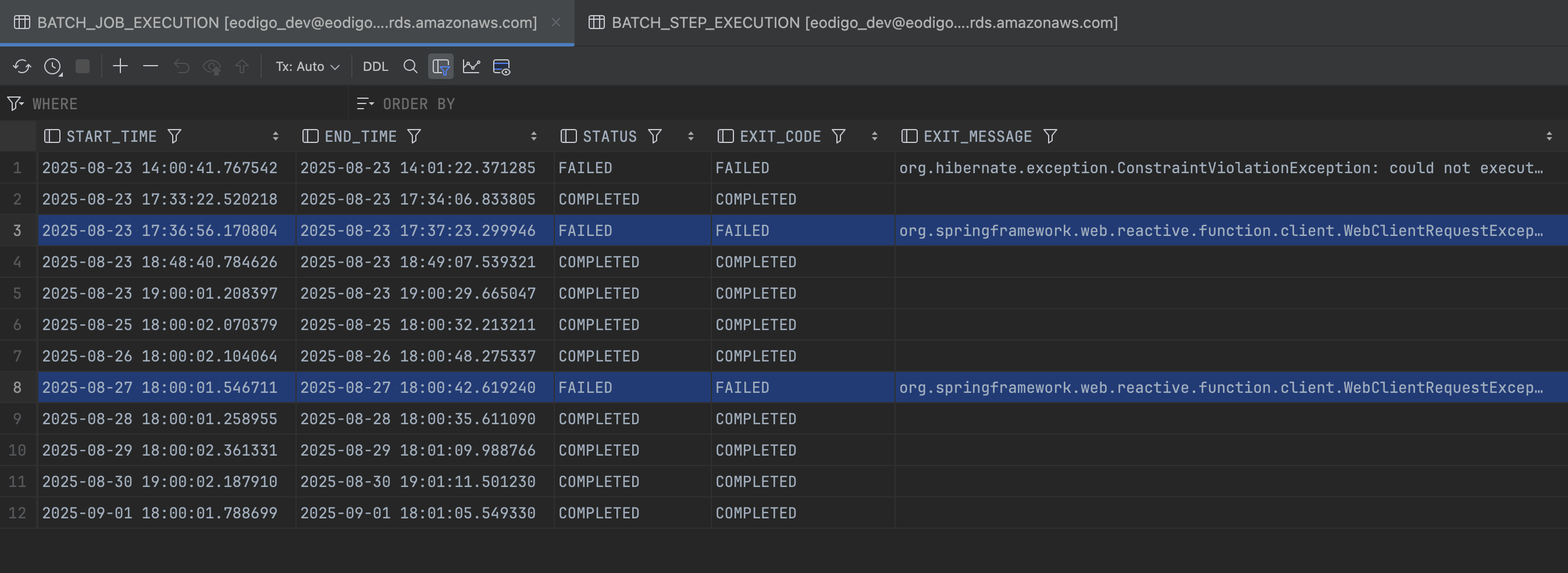
BATCH_JOB_EXECUTION테이블(Batch Job 실행 정보가 저장된 메타 테이블)을 확인하였고, 총 세 차례의 실패가 발생한 것을 확인했다.![batch_log 2]() BATCH_JOB_EXECUTION (2)
BATCH_JOB_EXECUTION (2)또한 그중 두 차례가
WebClientRequestException로 인한 실패라는 것을 발견했다.원인 분석
Reactor Netty 공식 문서와 GitHub reactor-netty 리포지토리에 등록된 issue를 찾아보니, 유사한 이슈에 대해 서버나 중간 네트워크 장비(로드밸런서, 프록시 등)의 유휴 시간 제한(Idle Timeout) 정책을 주된 원인으로 꼽았다.
보다 정확한 원인 분석을 위해서는
tcpdump로 네트워크 패킷을 직접 분석해야 했지만, 해당 시점에는 분석에 제약이 있었다. 그 대신 배치 작업의 특성을 바탕으로 원인을 가정한 뒤, 문제가 해결되는지를 확인하는 식으로 검증하기로 했다.배치 작업은 연결이 유휴 상태에 빠질 틈 없이 단시간에 대량의 API 요청을 보낸다. 따라서 문서에서 언급된 ‘Idle Timeout’보다는, 요청이 집중되는 순간 서버의 ‘트래픽 제어(Throttling)’ 정책에 걸렸을 가능성이 높다고 판단했다. 이 외에도 일시적인 네트워크 불안정도 원인이 될 수 있다고 가정했다.
해결
이 문제를 해결하기 위해 두 가지 조치를 취했다.
- 속도 제어: 각 API 호출 사이에
Thread.sleep(200L)을 추가하여 서버에 가해지는 부하를 분산시켰다. - 재시도 로직 도입: 보다 근본적인 해결책으로, Spring Batch가 제공하는
faultTolerant기능을 활용했다. Step 설정에retryLimit(3)과retry(WebClientRequestException.class)를 추가하여, 특정 네트워크 예외가 발생했을 때 실패로 처리하지 않고 해당 Chunk를 최대 3회까지 자동으로 재시도하도록 구성했다.
1 2 3 4 5 6 7 8 9 10 11
// KamisDailyPriceBatchConfiguration.kt @Bean fun kamisDailyPriceSyncStep(): Step { return StepBuilder(STEP_NAME, jobRepository) .chunk<KamisDailyPriceApiData, DailyRegionalPrice>(CHUNK_SIZE, transactionManager) // ... reader, processor, writer .faultTolerant() // 재시도 기능 활성화 .retryLimit(3) // 최대 3회 재시도 .retry(WebClientRequestException::class.java) // 특정 예외에 대해서만 재시도 .build() }
- 속도 제어: 각 API 호출 사이에
이후 며칠동안 배치가 정상적으로 실행되는 것을 확인했다.
데이터 중복으로 인한 Unique Key 제약 조건 위반
현상
kamisDailyPriceSyncJob이 최초로 실행됐을때Duplicate entry ... for key 'uk_daily_price_product_region_date_market'예외가 발생하며 Step이 실패했다.1
org.hibernate.exception.ConstraintViolationException: could not execute statement [Duplicate entry '18-1-2025-08-22-RETAIL' for key 'daily_regional_price.uk_daily_price_product_region_date_market'] [insert into daily_regional_price (created_at,market_type,price,product_id,region_id,survey_date,updated_at) values (?,?,?,?,?,?,?)]
- 원인 분석
daily_regional_price테이블은(product_id, region_id, survey_date, market_type)조합을 Unique Key로 설정한 상태였다.1 2 3 4 5 6 7 8 9 10 11 12
@Entity @Table( name = "daily_regional_price", uniqueConstraints = [ UniqueConstraint( name = "uk_daily_price_product_region_date_market", columnNames = ["product_id", "region_id", "survey_date", "market_type"], ) ], ) class DailyRegionalPrice
그런데 Postman으로 API 응답 명세를 검토한 결과, 동일한 품목(e.g., 고구마)에 대해 ‘상품’, ‘중품’ 등 복수의 품질 등급(rank) 데이터가 하나의 배열에 포함되어 있었다. 이로 인해 제약 조건 위반이 발생한 것이었다.
KAMIS API 응답 예시
1 2 3 4 5 6 7 8
[ { "item_name": "고구마", "kind_name": "밤(1kg)", "rank": "상품", "dpr1": "5,370" }, { "item_name": "고구마", "kind_name": "밤(1kg)", "rank": "중품", "dpr1": "4,425" } ]
해결
KamisDailyPriceProcessor에서 서비스의 기준이 되는 ‘상품’ 등급의 데이터만 엔티티로 변환하고, 그 외 등급의 데이터는null을 반환하도록 필터링 로직을 추가했다. Spring Batch의 Chunk 모델에서 Processor가null을 반환하면, 해당 아이템은 Writer로 전달되지 않고 무시된다.1 2 3 4 5 6 7 8 9
// KamisDailyPriceProcessor.kt override fun process(wrapper: KamisDailyPriceApiData): DailyRegionalPrice? { val item = wrapper.item // '상품' 등급이 아니면 필터링 if (item.rank != "상품") { return null } // ... }
불필요한 I/O로 인한 효율 저하
문제 식별
kamisAnnualPriceSyncJob의 실행 로그를 분석하던 중, 연평균 가격 데이터를 제공하지 않는 품목(축산물,categoryCode: '500')에 대해서도 불필요한 API 호출이 발생하고 있음을 발견했다. 또한 API는 과거 6년치 데이터를 한 번에 반환하는데, 우리 로직은 현재 연도의 데이터만 필요함에도 불구하고 불필요한 데이터를 가공하고 있었다.해결
- API Call 최적화:
ItemReader인JpaPagingItemReader의 JPQL 쿼리에WHERE p.categoryCode != '500'조건을 추가하여 API를 호출할 대상을 사전에 필터링했다. - DB Update 최적화:
ItemProcessor로직을 수정하여, API 응답 데이터 중 현재 연도(survey_year)에 해당하는 데이터만 필터링하여 엔티티로 변환하도록 개선했다. 이로써 불필요한 데이터 처리 및 DB UPDATE 연산을 제거할 수 있었다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// KamisAnnualPriceBatchConfiguration.kt (Reader 최적화) @Bean fun kamisAnnualPriceReader(): ItemReader<Product> { return JpaPagingItemReaderBuilder<Product>() // ... // '축산물' 카테고리는 조회 대상에서 제외 .queryString("SELECT p FROM Product p WHERE p.categoryCode != '500' ORDER BY p.id ASC") .build() } // KamisAnnualPriceProcessor.kt (Processor 최적화) private fun convertToEntities(...) { val entities = priceItems .filter { it.div == currentYear } // 현재 연도 데이터만 필터링 .mapNotNull { /* ... to Entity ... */ } // ... }
- API Call 최적화:
결론
이번 프로젝트를 통해 Spring Batch 기반의 ETL 파이프라인을 성공적으로 구축하여, 서비스의 핵심인 가격 데이터를 매일 안정적으로 자동 동기화하는 시스템을 완성할 수 있었다. 이 과정에서 다음과 같은 것들을 배웠다.
- 실용적 아키텍처 설계의 중요성: 프로젝트의 현재 규모와 단계를 객관적으로 분석하고, 그에 맞는 기술을 선택하는 것이 빠른 개발 속도와 효율적인 자원 사용의 핵심임을 알게됐다.
- 외부 시스템 연동의 안정성 확보: 외부 API 연동은 항상 실패 가능성을 내포하고 있으며, 재시도(Retry)와 같은 방어적 프로그래밍 패턴을 통해 시스템의 안정성을 높일 수 있다는 것을 체감했다.
- 프레임워크의 깊이 있는 활용: Spring Batch가 제공하는
faultTolerant,JpaPagingItemReader, Chunk 기반 처리 모델 등을 적극적으로 활용함으로써, 복잡한 비기능적 요구사항을 쉽게 해결하고 비즈니스 로직 자체에 더 집중할 수 있었다.