이 글은 Spring Batch를 프로젝트에 도입하게 된 배경과 아키텍처 설계 과정에 대해 다루고 있습니다.
배경
어디GO ‘상품 가격 탐색’ 기능에서의 핵심은 데이터의 최신성과 정확성이다. 가격 랭킹, 가격 추이 기능은 최신 상품 가격을 기반으로 제공되어야 한다. 이를 위해 농수산물 유통정보(KAMIS) Open API를 사용, 매일 상품의 가격 데이터를 데이터베이스로 동기화해야 했다.
문제는 처리할 데이터의 규모였다. 일일 가격의 경우, 252개 상품 x 24개 지역으로 매일 약 6,000건의 신규 데이터(INSERT)가 발생하며, 연평균 가격은 252개 상품에 대한 데이터 갱신(UPDATE)이 필요했다.
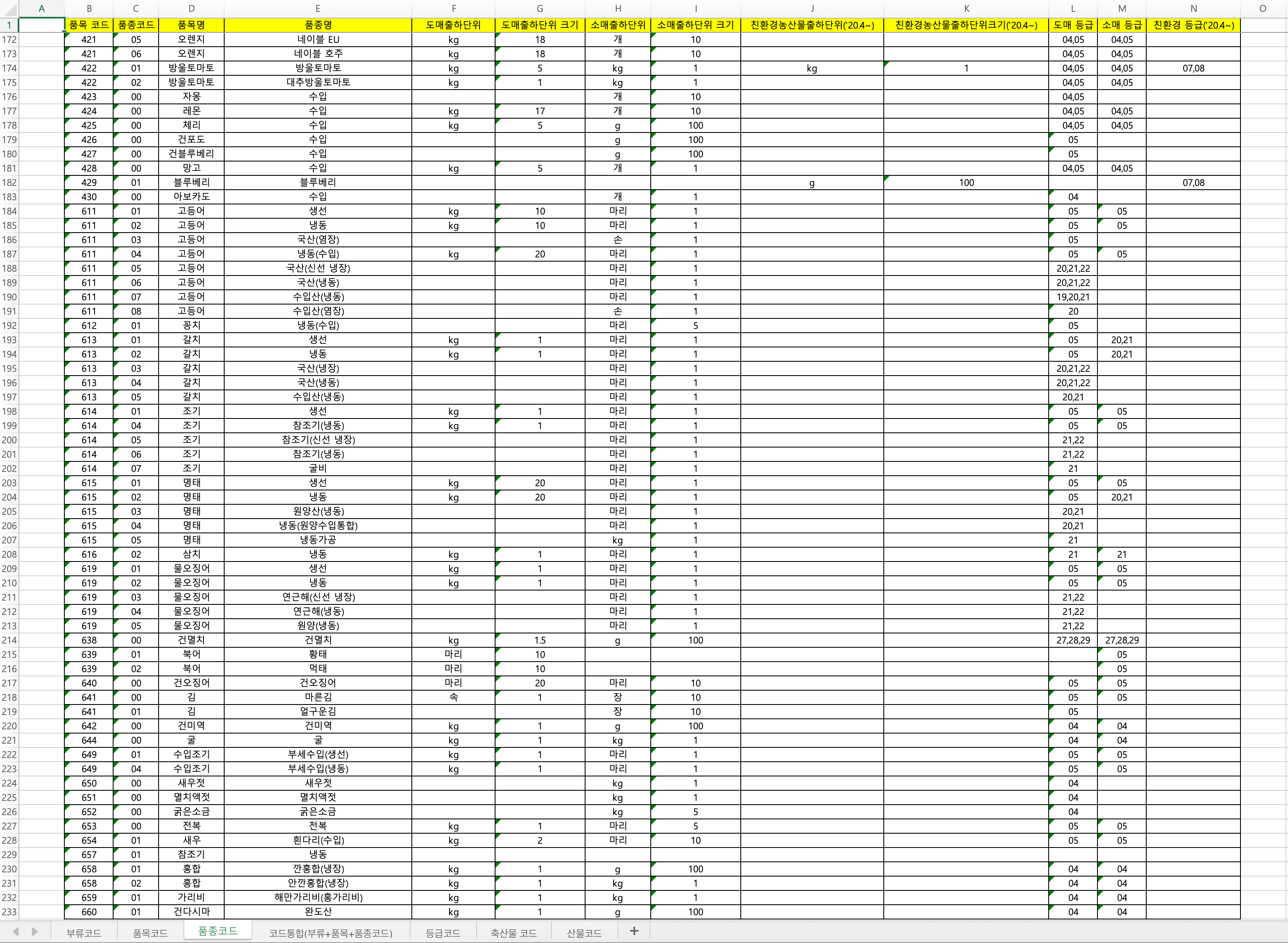 KAMIS 농축산물 품목 데이터
KAMIS 농축산물 품목 데이터
단순히 @Scheduled 어노테이션과 WebClient를 조합한 서비스 메서드만으로는 이 요구사항을 안정적으로 충족시키기 어렵다고 판단했다. 대량의 데이터를 처리하는 과정에서 부분적인 실패가 전체 작업을 중단시키거나, 네트워크 오류로 인해 작업을 처음부터 다시 시작해야 하는 문제가 발생할 수 있기 때문이다. 따라서 Spring Batch를 도입하기로 결정했다.
Spring Batch란?

주요 특징
Spring Batch는 사용자의 개입 없이 대규모 데이터를 안정적으로 일괄 처리하는 데 특화된 경량 프레임워크이다. 주로 데이터 정산, 변환, 마이그레이션과 같이 주기적이고 대량의 데이터를 다루는 작업에 적합하다.
핵심 기능으로는 트랜잭션 관리, 청크(Chunk) 기반 처리, 재시도 기능 등이 있다. Spring Batch는 스케줄링 기능을 포함하고 있지 않으므로, Quartz와 같은 별도의 스케줄링 프레임워크와 함께 사용되어야 한다.
동작 방식
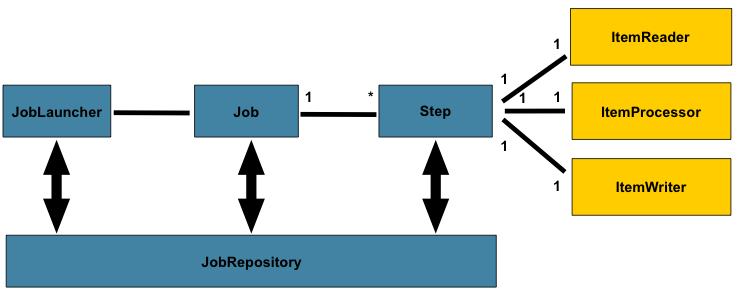
Spring Batch의 동작 방식은 다음과 같다.
JobLauncher가 Job 실행
배치 프로세스는 JobLauncher에 의해 시작된다. JobLauncher는 실행할 Job과 필요한 파라미터(JobParameters)를 받는다.JobRepository가 실행 정보 생성
JobLauncher는 Job을 실행하기 직전, JobRepository에 접근하여 JobExecution이라는 작업 실행 정보를 생성하고 기록한다. JobRepository는 이처럼 배치 작업의 모든 상태와 메타데이터를 저장하는 저장소이다.Job과 Step 실행
Job은 배치 작업 전체를 의미하며, 내부에 하나 이상의 Step을 포함한다. Job이 시작되면 내부의 Step들이 순차적으로 실행된다.Step 내에서의 데이터 처리 (Read → Process → Write)
실질적인 데이터 처리는 Step 안에서 이루어진다. 가장 일반적인 청크 기반 Step은 아래와 같이 동작한다.- ItemReader: 데이터 소스에서 데이터를 한 건씩 읽는다.
- ItemProcessor: 읽어온 데이터를 가공한다. (선택 사항)
- ItemWriter: 가공된 데이터들을 정해진 청크(chunk) 단위만큼 모아서 한 번에 대상에 쓴다.
이 모든 처리 과정에서 읽은 데이터 수, 처리 상태 등은 지속적으로 JobRepository에 기록된다. 만약 작업이 실패하면, JobRepository에 저장된 마지막 성공 지점을 기반으로 작업을 재시작할 수 있다.
Batch Application 아키텍처 설계
본격적인 구현에 앞서, 배치 애플리케이션의 전체 구조와 운영 방식을 결정하는 것은 장기적인 유지보수성과 확장성에 큰 영향을 미친다. 본 프로젝트에서는 세 가지 주요 설계 포인트를 중점적으로 고민했다.
배치 모듈의 위치: 통합(Integrated) vs. 분리(Separated) 구성
가장 먼저 고민한 것은 ‘배치 모듈을 API 애플리케이션과 함께 둘 것인가, 아니면 별도의 애플리케이션으로 분리할 것인가’였다.
- 분리 구성: API 서버와 배치 서버를 별도의 인스턴스로 구성한다. 배치 작업이 API 서버의 성능에 영향을 주지 않도록 자원을 완벽히 격리할 수 있다는 장점이 있다.
- 통합 구성: 단일 Spring Boot 애플리케이션 안에 API 로직과 배치 로직을 함께 포함한다. 구조가 단순하고, CI/CD 파이프라인 관리가 용이하며, 추가적인 인프라 비용이 발생하지 않는다.
MVP 단계인 우리 프로젝트의 트래픽 규모와, 사용자가 거의 없는 새벽 시간대에 배치를 실행하는 운영 계획을 고려했을 때 자원 경합이 발생할 가능성은 낮다고 판단했다. 따라서 개발 속도와 배포의 단순성, 비용 효율성을 극대화하기 위해 단일 애플리케이션 통합 구조를 최종적으로 채택했다.
스케줄링 구현 방식: Spring @Scheduled vs. Quartz
다음은 주기적인 실행을 담당할 스케줄러 선택이었다.
- Spring
@Scheduled: Spring 프레임워크에 내장된 기능으로, 어노테이션 기반으로 매우 간단하게 스케줄링을 구현할 수 있다. 스케줄 정보는 메모리 기반으로 동작한다. - Quartz: 스케줄링에 특화된 강력한 라이브러리로, 스케줄 정보를 데이터베이스에 저장하여 클러스터링 환경에서도 작업의 중복 실행을 방지하고, 정교한 제어가 가능하다.
현재 우리 서비스의 인프라는 단일 EC2 인스턴스 환경이다. 따라서 @Scheduled의 가장 큰 제약사항인 ‘다중 서버 환경에서의 중복 실행’ 문제가 발생하지 않는다. 더 복잡한 설정과 별도의 DB 테이블이 필요한 Quartz를 도입하는 것은 현 단계에서 오버 엔지니어링이라 판단했고, 더 가볍고 설정이 간편한 Spring @Scheduled를 사용하기로 결정했다.
1
2
3
4
5
// EodigoApplication.kt
@EnableScheduling // 스케줄링 기능 활성화
@EnableJpaAuditing
@SpringBootApplication
class EodigoApplication
마스터 데이터 초기화 전략: Batch Job vs. ApplicationRunner
가격 데이터와 달리 거의 변경되지 않는 product, region과 같은 마스터 데이터는 어떤 방식으로 초기화할지 고민이 필요했다. 일회성 데이터 적재를 주기적인 배치 Job에 포함하는 것은 역할과 책임의 분리 원칙에 위배된다고 생각했다.
따라서 애플리케이션이 구동될 때, 테이블이 비어 있는 경우에만 단 한 번 실행되어 외부 API를 통해 마스터 데이터를 적재하는 ApplicationRunner를 이용한 데이터 시딩(Seeding) 방식을 채택했다. 이로써 주기적으로 실행되는 배치 로직과 일회성 초기화 로직을 명확히 분리할 수 있었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// com/eodigo/common/initializer/ProductMasterInitializer.kt
@Component
@Profile("!test")
class ProductMasterInitializer(...) : ApplicationRunner {
@Transactional
override fun run(args: ApplicationArguments?) {
// DB에 데이터가 이미 있는지 확인
if (productRepository.existsBySource(ProductSource.KAMIS)) {
log.info("[ProductMasterInitializer] KAMIS product master data already exists. Skipping.")
return
}
// API를 호출하여 Product 마스터 데이터 적재
// ...
}
}
API 통신을 위한 WebClient 선택
배치 파이프라인, 특히 ItemReader와 ItemProcessor의 성능과 안정성은 외부 API와 어떻게 통신하는지에 크게 의존한다. 본 프로젝트에서는 Spring 환경에서 HTTP 통신을 위해 WebClient를 채택했다. 그 이유를 이해하기 위해 먼저 RestTemplate, WebClient, 그리고 HttpClient의 관계를 짚어볼 필요가 있다.
RestTemplate과거 Spring의 표준 HTTP 클라이언트였다. 동작 방식이 동기(Synchronous) & 블로킹(Blocking) 방식이라, API에 요청을 보내면 응답이 올 때까지 현재 스레드가 대기(Block)해야만 한다. 코드가 직관적이지만, 다수의 요청을 동시에 처리해야 하는 환경에서는 스레드 자원을 비효율적으로 사용하여 성능 저하의 원인이 될 수 있다. 현재는 유지보수 모드(Maintenance Mode)로 전환되었다.WebClientSpring 5부터 도입된 최신 HTTP 클라이언트이다. 비동기(Asynchronous) & 논블로킹(Non-blocking) 방식으로 동작하는 것이 가장 큰 특징이다. 요청을 보낸 스레드가 응답을 기다리지 않고 즉시 다른 작업을 수행할 수 있어, 시스템 자원을 훨씬 효율적으로 사용한다.WebClient는 고수준의 추상화 도구이며, 내부적으로HttpClient엔진을 사용하여 실제 통신을 수행한다.HttpClient: 네트워크 소켓을 열고 데이터를 바이트 단위로 주고받는, 실제 통신의 가장 낮은 레벨을 담당하는 핵심 실행 엔진이다. Apache HttpClient, Netty HttpClient 등 여러 구현체가 존재한다.
일일 가격 수집 Job(kamisDailyPriceSyncJob)은 수백 번의 API 호출을 수행해야 한다. 만약 RestTemplate을 사용했다면, 매 호출마다 스레드가 블로킹되어 전체 배치 수행 시간이 길어지고 시스템에 부담을 줄 수 있었다.
이러한 이유로, 본 프로젝트에서는 비동기/논블로킹 방식의 WebClient를 API 통신 클라이언트로 최종 선택했다. 또한 단순히 기본 WebClient를 사용하는데 그치는 것이 아닌, Reactor Netty의 HttpClient를 직접 설정하여 WebClient의 통신 엔진으로 주입하는 방식을 사용했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// config/WebClientConfig.kt
@Configuration
class WebClientConfig(private val objectMapper: ObjectMapper) {
@Bean
fun webClient(): WebClient {
// 1. 통신 엔진(HttpClient) 생성 및 설정
val httpClient =
HttpClient.create()
.followRedirect(true) // 302 Redirect 자동 처리
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000) // Connection Timeout 설정
.responseTimeout(Duration.ofSeconds(10))
// ... (TEXT_PLAIN 컨텐츠 타입 처리 로직)
// 2. WebClient에 위에서 설정한 HttpClient 엔진을 주입
return WebClient.builder()
.baseUrl("<http://www.kamis.or.kr>")
.clientConnector(ReactorClientHttpConnector(httpClient))
.exchangeStrategies(exchangeStrategies)
.build()
}
}
위 설정 코드를 통해 우리는 WebClient라는 고수준의 API 클라이언트에, 타임아웃과 같은 세부 설정이 완료된 Netty HttpClient 엔진을 장착했다. 이를 통해 외부 API 통신 과정에서의 안정성과 효율성을 모두 확보할 수 있었다.
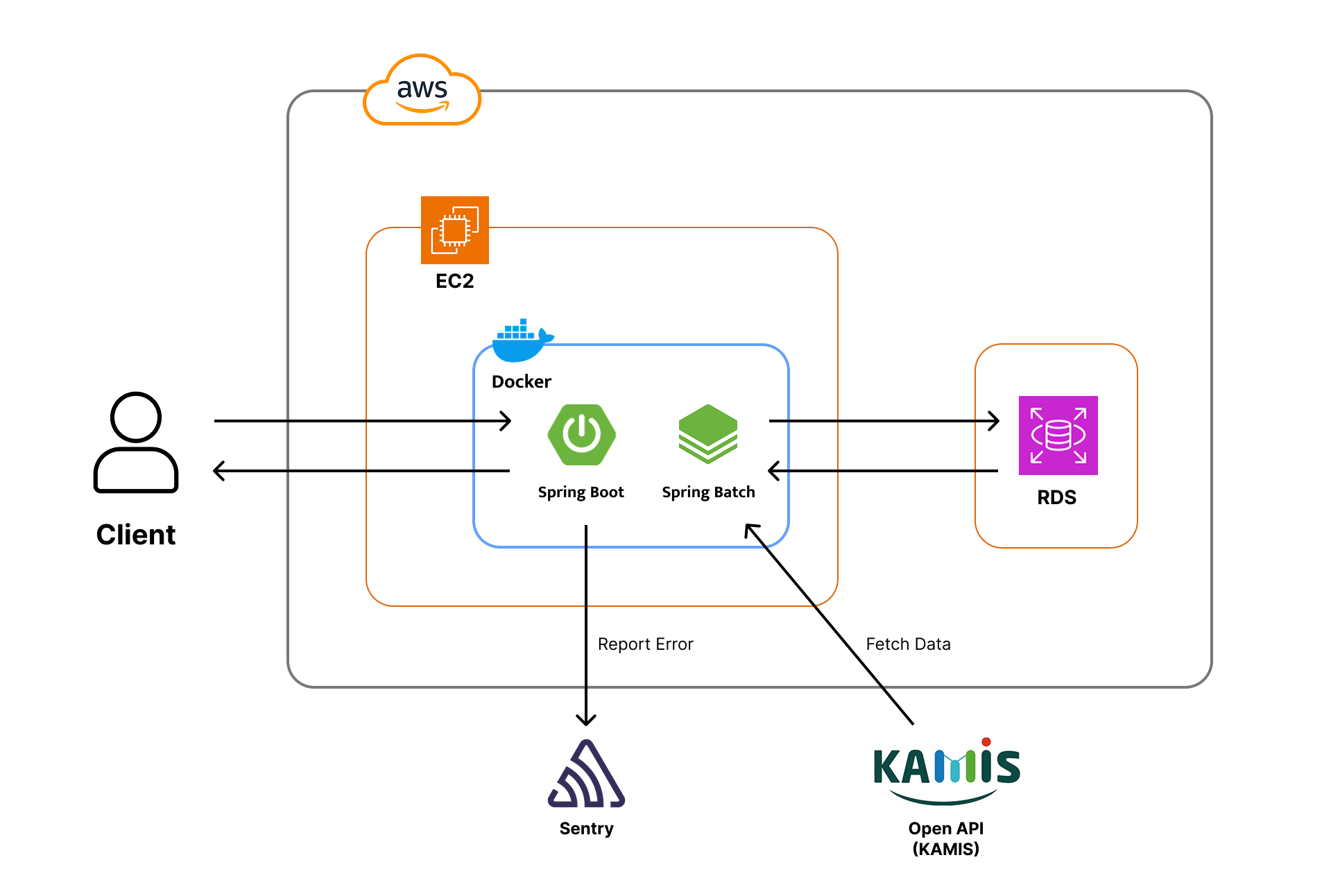 batch application 아키텍처
batch application 아키텍처
다음 글에서는 이러한 설계를 바탕으로 구현한 Spring Batch Job에 대해 이야기할 계획이다.