이전 글에서 이어지는 글입니다.
모니터링 대상 서버 연동
이제 모니터링 대상인 ‘어디GO’ 서버가 자신의 상태 정보를 외부에 공개하도록 설정할 차례다.
서버 인프라 메트릭 수집 (Node Exporter)
서버의 CPU, 메모리, 네트워크 등 기본적인 하드웨어 및 OS 정보를 수집하기 위해 node_exporter를 사용했다. ‘어디GO’ 서버에 SSH로 접속하여 아래 Docker 명령어로 node_exporter 컨테이너를 간단하게 실행했다.
1
2
3
4
5
6
# '어디GO' 서버에서 실행
docker run -d \\
--name node_exporter \\
--restart unless-stopped \\
-p 9100:9100 \\
prom/node-exporter
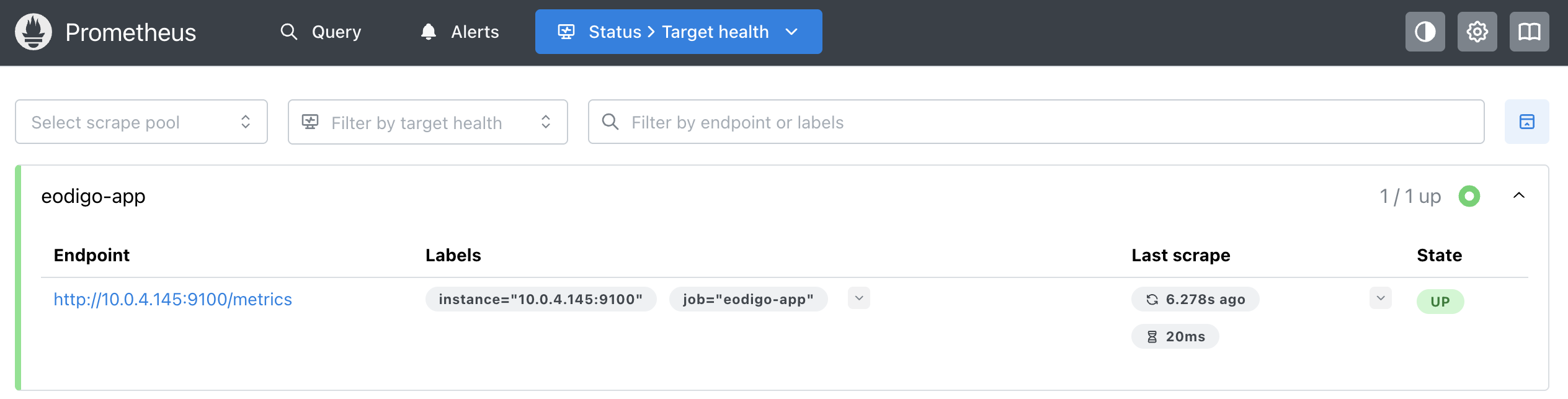
이후 ‘어디GO’ 서버의 보안 그룹 인바운드 규칙에 9100번 포트를 추가했다. 이때 소스를 위치 무관(0.0.0.0/0)이 아닌, 모니터링 서버로 지정하여 허가된 서버만 메트릭 정보에 접근할 수 있도록 하였다.
마지막으로 모니터링 서버의 prometheus.yml 파일에 어디GO 서버를 새로운 수집 대상으로 추가하고 Prometheus를 재시작했다.
1
2
3
4
5
# prometheus.yml
# ... (기존 설정)
- job_name: 'eodigo-app'
static_configs:
- targets: ['[어디GO 서버의 프라이빗 IP]:9100']

Prometheus 웹 UI에서 eodigo-app의 상태가 UP으로 표시된 것을 확인할 수 있다.
애플리케이션 메트릭 수집 (Spring Boot Actuator)
인프라뿐만 아니라, 애플리케이션 내부에서 어떤 일이 일어나는지 파악하는 것도 매우 중요하다. Spring Boot 프로젝트에서는 Actuator와 Micrometer 의존성을 추가하여 JVM 상태, API 요청/응답 현황 등 다양한 애플리케이션 메트릭을 손쉽게 노출할 수 있다.
먼저 build.gradle.kts에 의존성을 추가한다.
build.gradle.kts
1
2
implementation("org.springframework.boot:spring-boot-starter-actuator")
implementation("io.micrometer:micrometer-registry-prometheus")
다음으로 application.yml에서 /actuator/prometheus 엔드포인트를 활성화하고, 기존 API 포트(8080)와 분리된 9000번 포트를 Actuator 전용 포트로 설정했다.
application.yml
1
2
3
4
5
6
7
8
9
10
management:
endpoints:
web:
exposure:
include: "health,prometheus"
server:
port: 9000
metrics:
tags:
application: "eodigo-app"
코드를 수정한 뒤 CI/CD 파이프라인을 통해 재배포했다. 배포가 완료된 후, node_exporter 때와 마찬가지로 ‘어디GO’ 서버의 보안 그룹에 9000번 포트를 모니터링 서버에만 허용하도록 추가하고, prometheus.yml에 애플리케이션 메트릭 수집 잡을 추가했다.
1
2
3
4
5
6
# prometheus.yml
# ... (기존 설정)
- job_name: 'eodigo-application'
metrics_path: /actuator/prometheus
static_configs:
- targets: ['[어디GO 서버 프라이빗 IP]:9000']
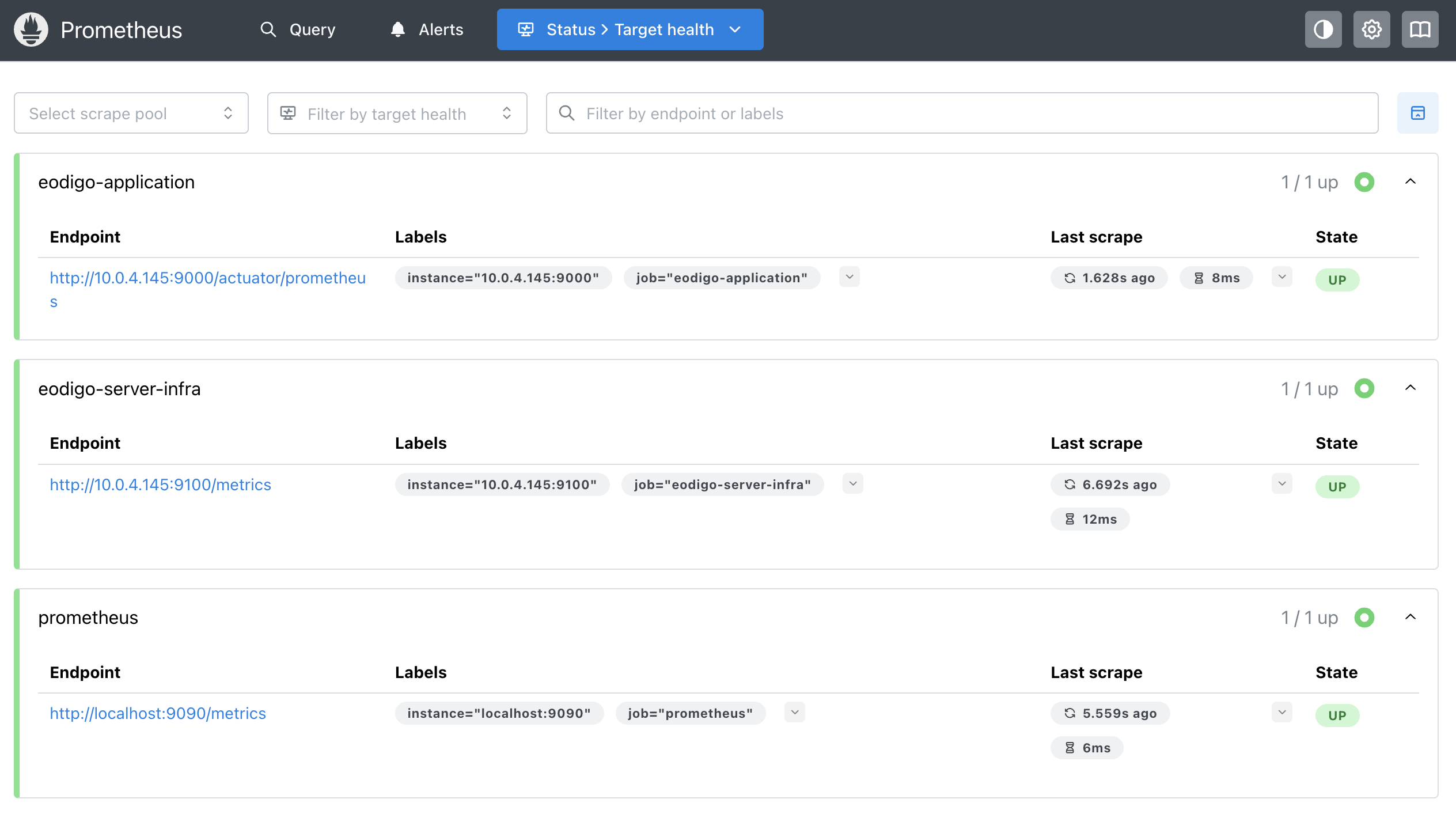
Prometheus를 재시작하자, eodigo-application 잡 역시 ‘UP’ 상태가 되었다.
Grafana 대시보드 시각화
Prometheus 데이터 소스 연동
이제 Prometheus가 모으고 있는 데이터를 사람이 알아보기 쉽게 시각화할 차례다. 브라우저에서 Grafana(http://[모니터링 서버 IP]:3000)에 접속하였다.
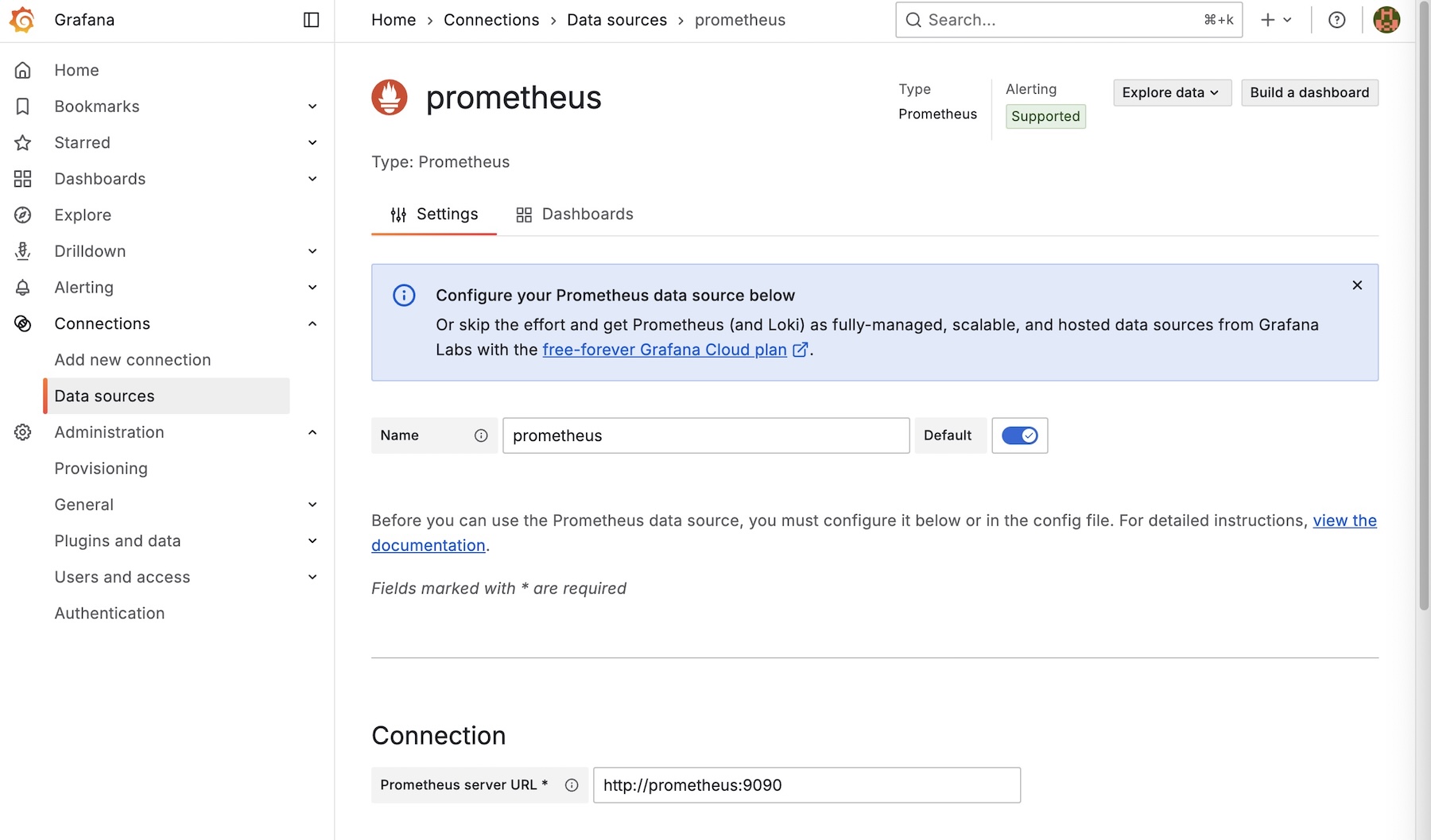
가장 먼저 할 일은 Grafana에 데이터 소스를 연결하는 것이다. Prometheus를 선택하고, URL을 http://prometheus:9090으로 입력했다. localhost가 아닌 서비스 이름 prometheus를 사용한 이유는, 두 컨테이너가 docker-compose에 의해 동일한 내부 네트워크에 속해 있어 서비스 이름으로 서로를 찾을 수 있기 때문이다.
‘Save & test’ 버튼을 눌러 성공 메시지를 확인하고 연동을 마쳤다.
인프라 및 JVM 대시보드 적용
Grafana의 가장 큰 장점은 다양한 대시보드를 Import하여 사용할 수 있다는 점이다. 나는 node_exporter와 Spring Boot Actuator를 위한 대시보드 두 개를 설치했다.
Node Exporter Full (ID: 1860): CPU, Memory, Disk I/O, Network 등 서버의 전반적인 인프라 상태를 보여주는 대시보드
![grafana_dashboard-1.jpg]()
JVM (Micrometer) (ID: 4701): JVM 메모리 사용량, 스레드 상태, GC(Garbage Collection) 현황 등 애플리케이션의 상세 지표를 보여주는 대시보드
![grafana_dashboard-2.jpg]()
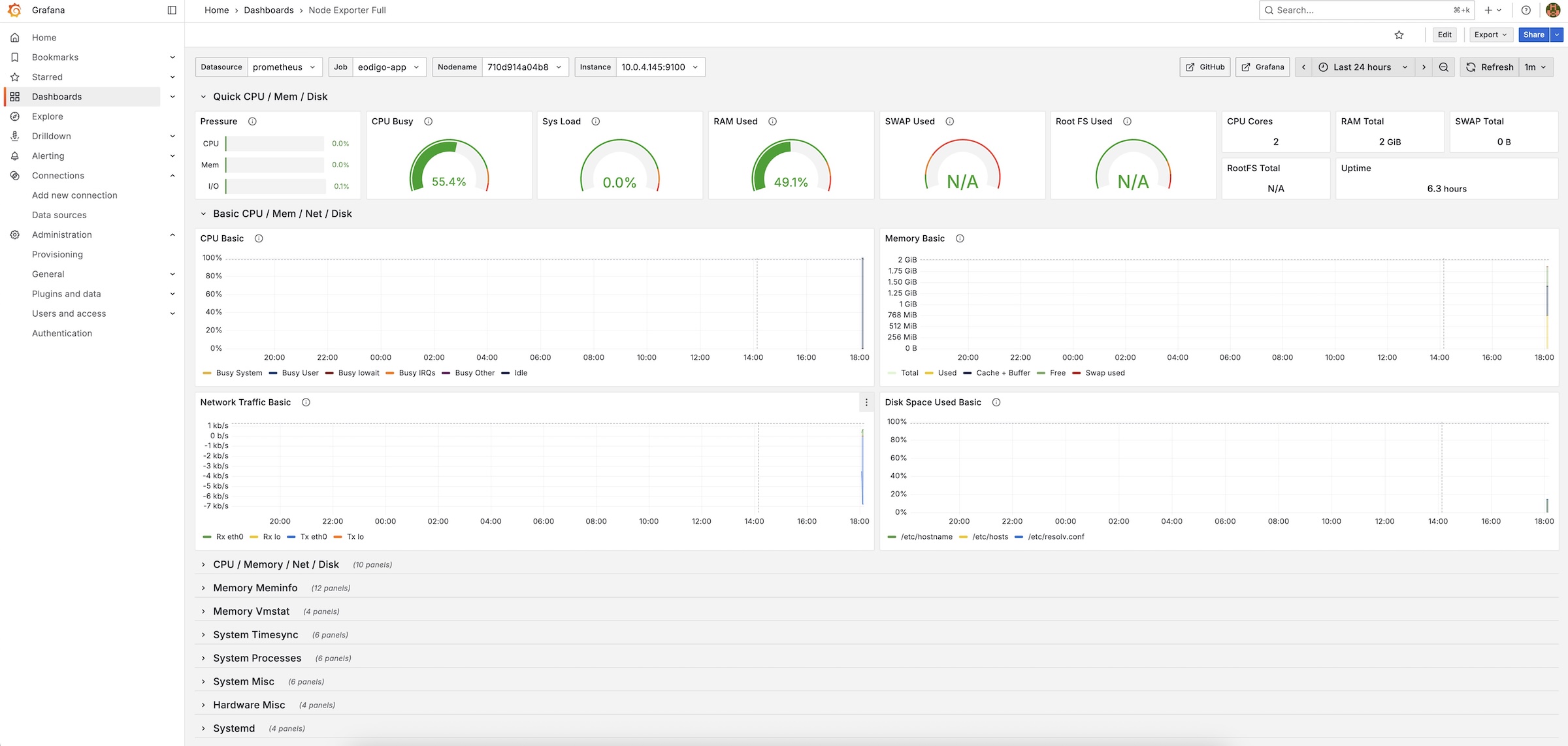
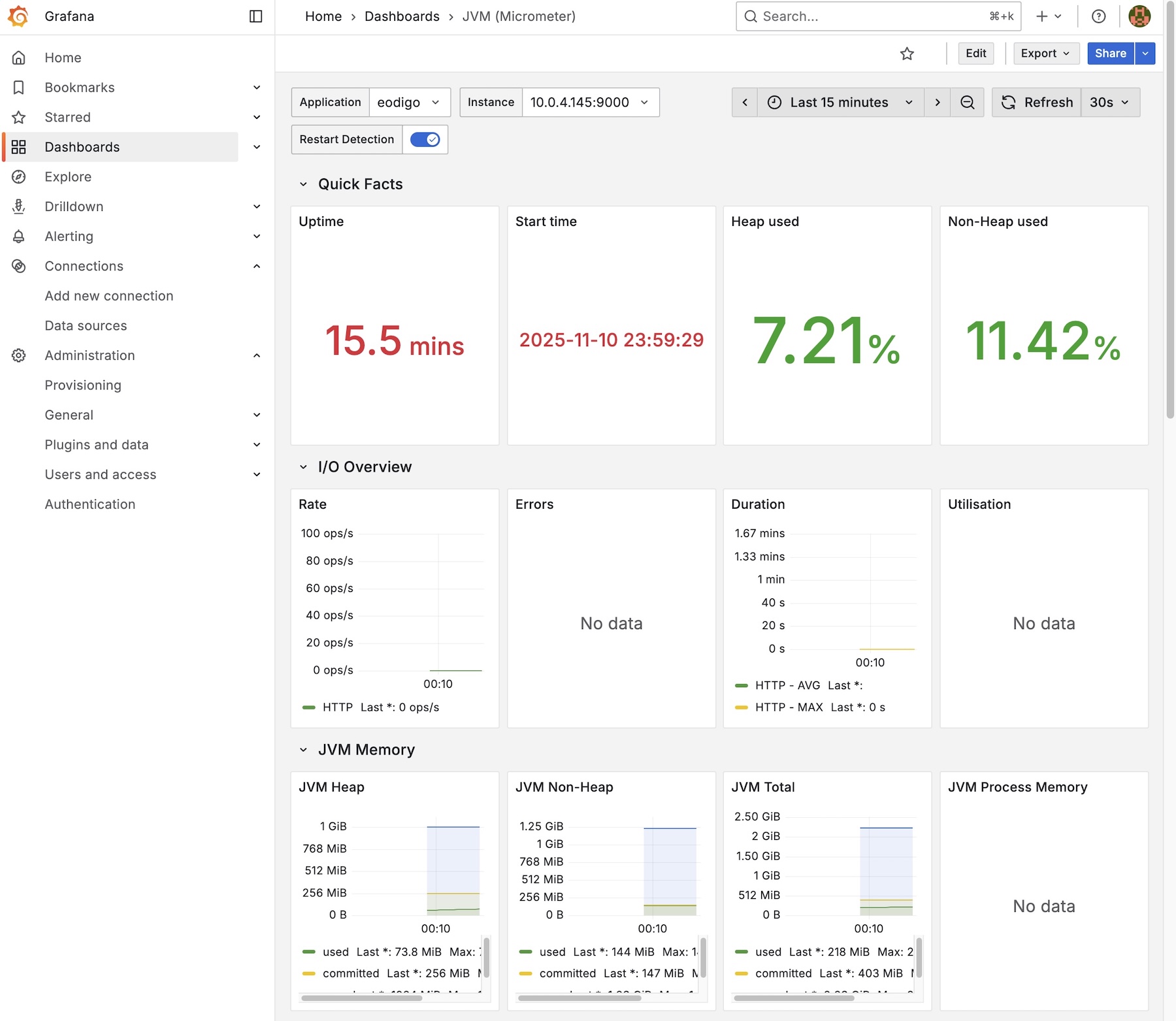
위와 같이 서버의 상태를 나타내는 다양한 그래프들을 확인할 수 있다.
주요 이슈
모니터링 시스템 구축이 순조롭게 진행되는 듯했지만, node_exporter 연동 단계에서 예상치 못한 난관에 부딪혔다. Prometheus Targets 페이지에서 eodigo-app의 상태가 계속해서 DOWN으로 표시되며 데이터 수집에 실패하는 문제가 발생했다.
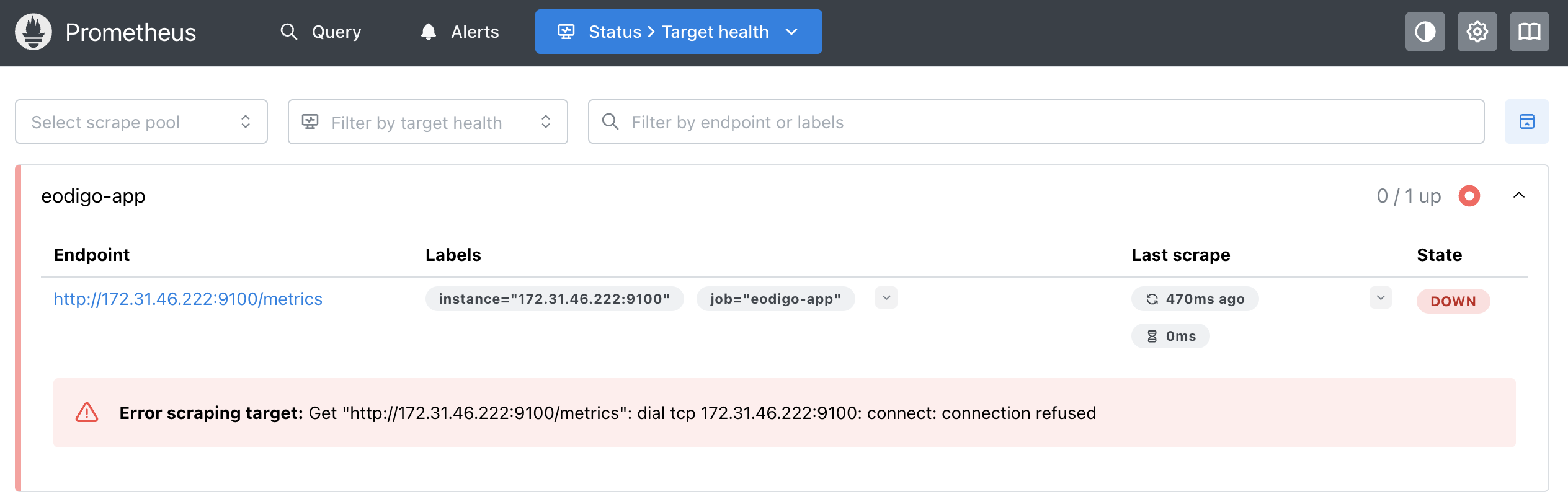
문제 현상
가장 먼저 의심한 것은 두 서버 간의 네트워크 연결성이었다. 이를 확인하기 위해 모니터링 서버에서 ‘어디GO’ 서버의 node_exporter 엔드포인트로 직접 curl 요청을 실행했다.
1
curl http://10.0.4.145:9100/metrics
정상이라면 Prometheus가 수집하는 텍스트 형식의 메트릭 데이터가 즉시 출력되어야 했다. 하지만 터미널은 아무런 출력을 내지 못한 채, 응답을 기다리는 행(hang) 상태에 빠졌다. 이는 요청 패킷이 목적지에 도달하지 못하고 중간 경로에서 유실되어 타임아웃(Connection Timeout)이 발생하고 있음을 시사했다.
추적 과정
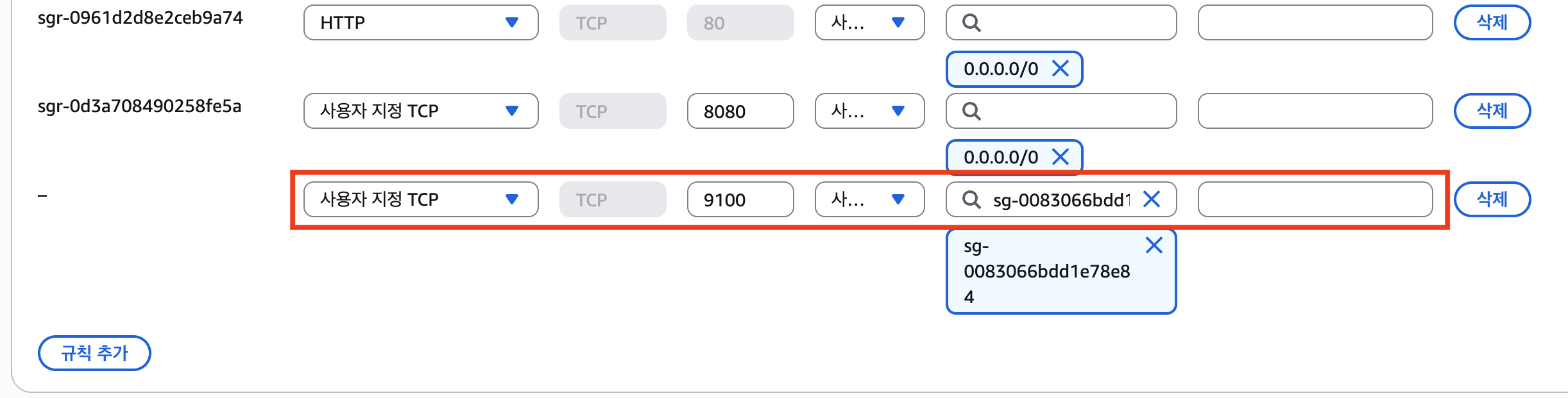
우선 ‘어디GO’ 서버의 보안 그룹 인바운드 규칙 설정을 점검했다. AWS 콘솔에서 확인한 결과, 9100번 포트에 대해 모니터링 서버의 Private IP(172.31.x.x)를 허용하도록 규칙은 정확히 설정되어 있었다.
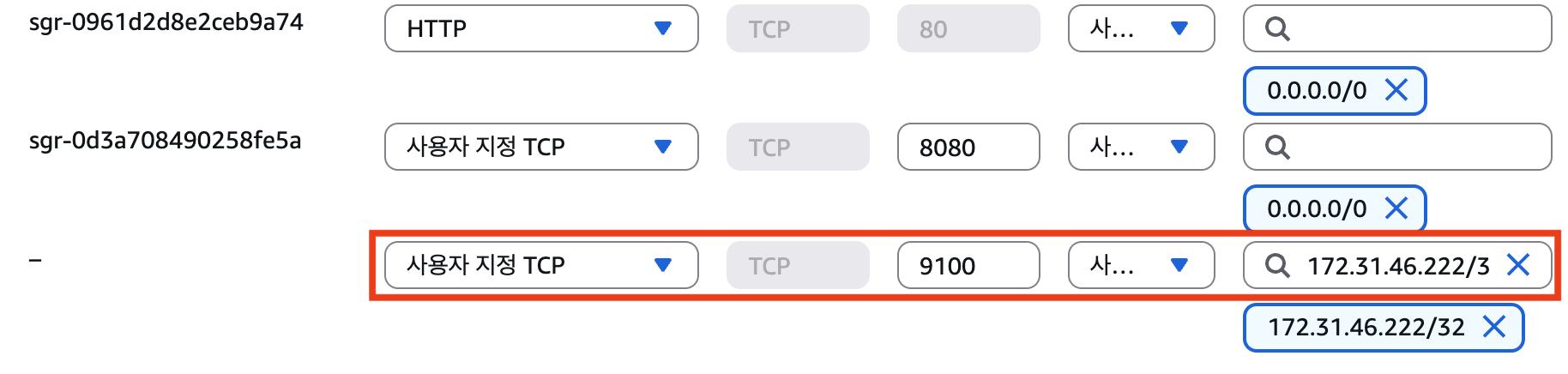
확신을 위해 IP 주소 대신 보안 그룹 ID를 소스로 참조하는 방식으로 규칙을 변경해 보았다. 모니터링 서버의 보안 그룹 ID(sg-xxxx)를 소스로 지정하고 저장 버튼을 누르는 순간, 결정적인 오류 메시지를 마주하게 되었다.
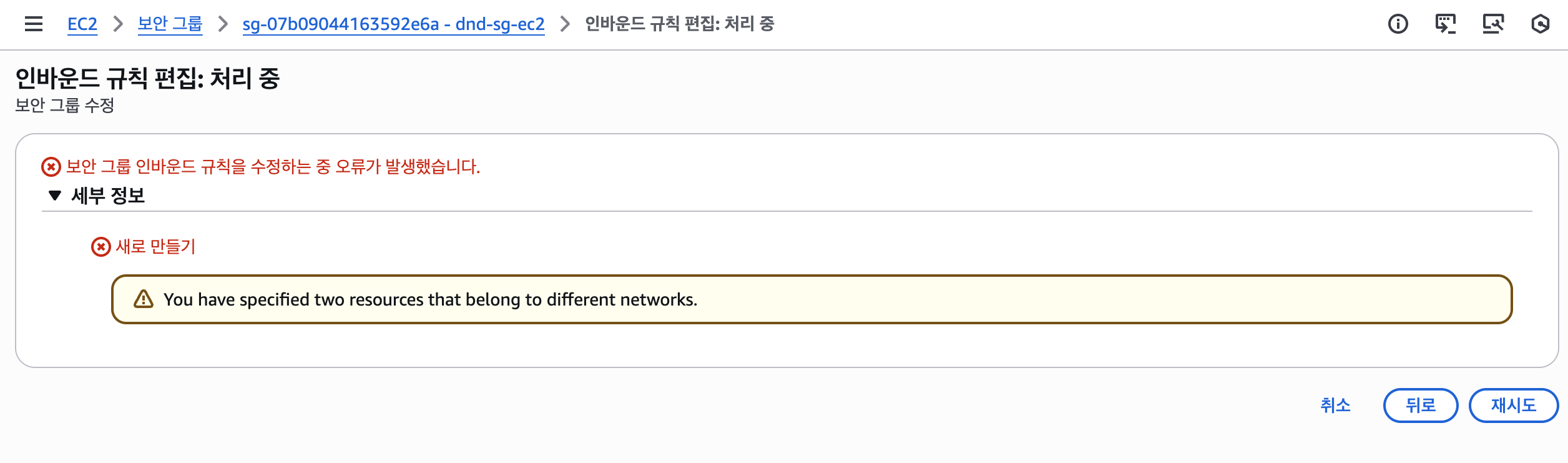
“You have specified two resources that belong to different networks.”
이 메시지는 두 리소스(보안 그룹)가 서로 다른 네트워크에 속해 있어 상호 참조가 불가능하다는 의미였다. 그제야 원인을 파악할 수 있었다. ‘어디GO’ 서버는 의도대로 dnd-project-vpc에 생성했지만, 모니터링 서버는 생성 과정에서 VPC 설정을 간과하여 AWS의 기본(default) VPC에 프로비저닝되었던 것이다.
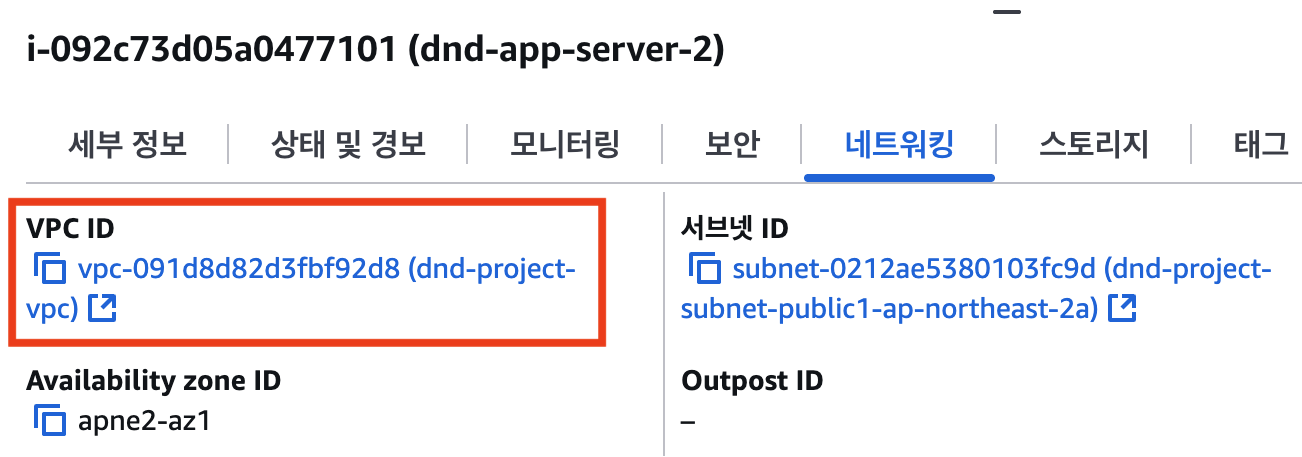 | 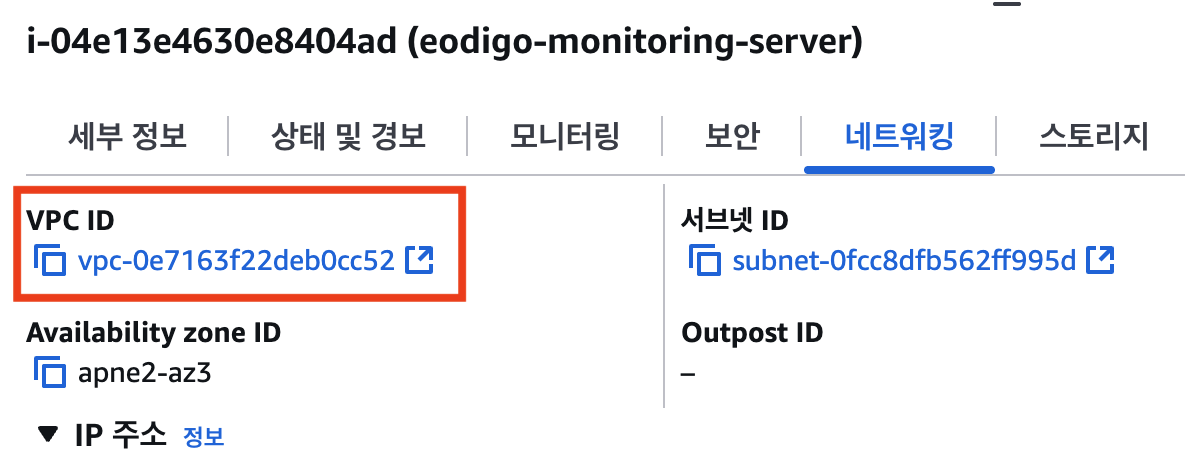 |
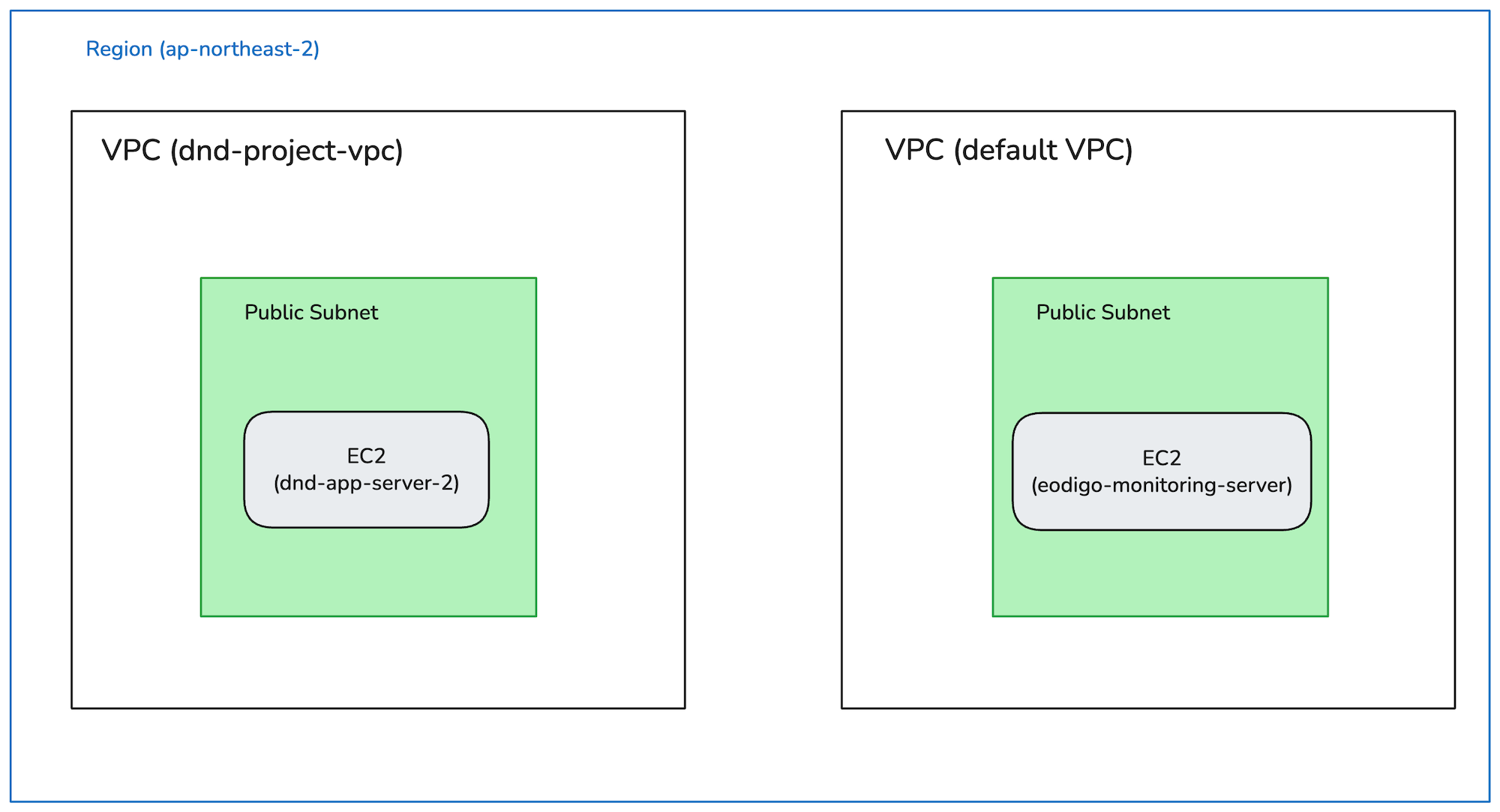 당시 VPC
당시 VPC
해결: EC2 인스턴스 이전
VPC(Virtual Private Cloud)는 AWS 클라우드 내에서 논리적으로 완전히 격리된 가상의 네트워크 공간이다. 서로 다른 VPC에 속한 인스턴스들은 기본적으로 사설 통신이 불가능하다. 내가 겪은 Connection Timeout 현상은 이 특성 때문에 발생한 것이었다. 아무리 보안 그룹에서 특정 IP나 보안 그룹을 허용해도, 두 서버는 애초에 서로 다른 네트워크에 존재하여 패킷이 도달할 수 없었던 것이다.
원인을 명확히 파악한 뒤 해결은 간단했다. 기본 VPC에 잘못 생성했던 모니터링 인스턴스를 종료하고, ‘어디GO’ 서버와 동일한 dnd-project-vpc 내에 새로운 인스턴스를 생성했다. 이후 동일한 과정을 거쳐 Prometheus를 재설정하자, Targets 페이지의 eodigo-app의 상태가 UP으로 바뀌었다.
마치며
이번 모니터링 시스템 구축을 통해 CPU 사용량이 급증하거나, 특정 API의 응답 시간이 길어지는 현상을 데이터 기반으로 파악하고, 문제의 원인을 추적할 수 있게 되었다.
또한 트러블슈팅을 통해 클라우드 리소스를 생성할 때는 리소스가 위치할 네트워크(VPC)와 서브넷을 명확하게 확인하는 습관이 매우 중요하다는 것을 체감했다. 이를 통해 클라우드 네트워킹의 기본 원리를 더 깊이 이해할 수 있었다.
현재 시스템은 데이터를 보고 문제가 생겼을 때 알아차리는 수준이다. 추후 Grafana의 Alerting 기능을 슬랙과 연동하는 등 자동화된 장애 감지 시스템을 구축할 계획이다.