들어가며
어디GO의 백엔드 MVP 개발은 완료됐지만 한 가지 문제가 남아있었다. 현재는 ‘서버가 잘 돌고 있는지’에 대해 명확하게 알기 어려웠다.
이러한 불확실성을 해소하고, 시스템의 안정성을 확보하기 위해 서버의 상태를 실시간으로 파악할 수 있는 모니터링 시스템을 구축하기로 결정했다. 업계 표준으로 널리 사용되는 프로메테우스(Prometheus)로 서버의 각종 지표(Metric)를 수집하고, 그라파나(Grafana)를 통해 이 데이터를 시각적으로 표현하는 것이 이번 목표이다.
이 글은 AWS 환경에서 별도의 모니터링 서버를 구축하고, 기존에 운영 중이던 Spring Boot 서버를 연동하여 인프라와 애플리케이션의 상태를 한눈에 파악하는 모니터링 시스템을 구축한 과정을 기록한 것이다.
모니터링 시스템 아키텍처 설계
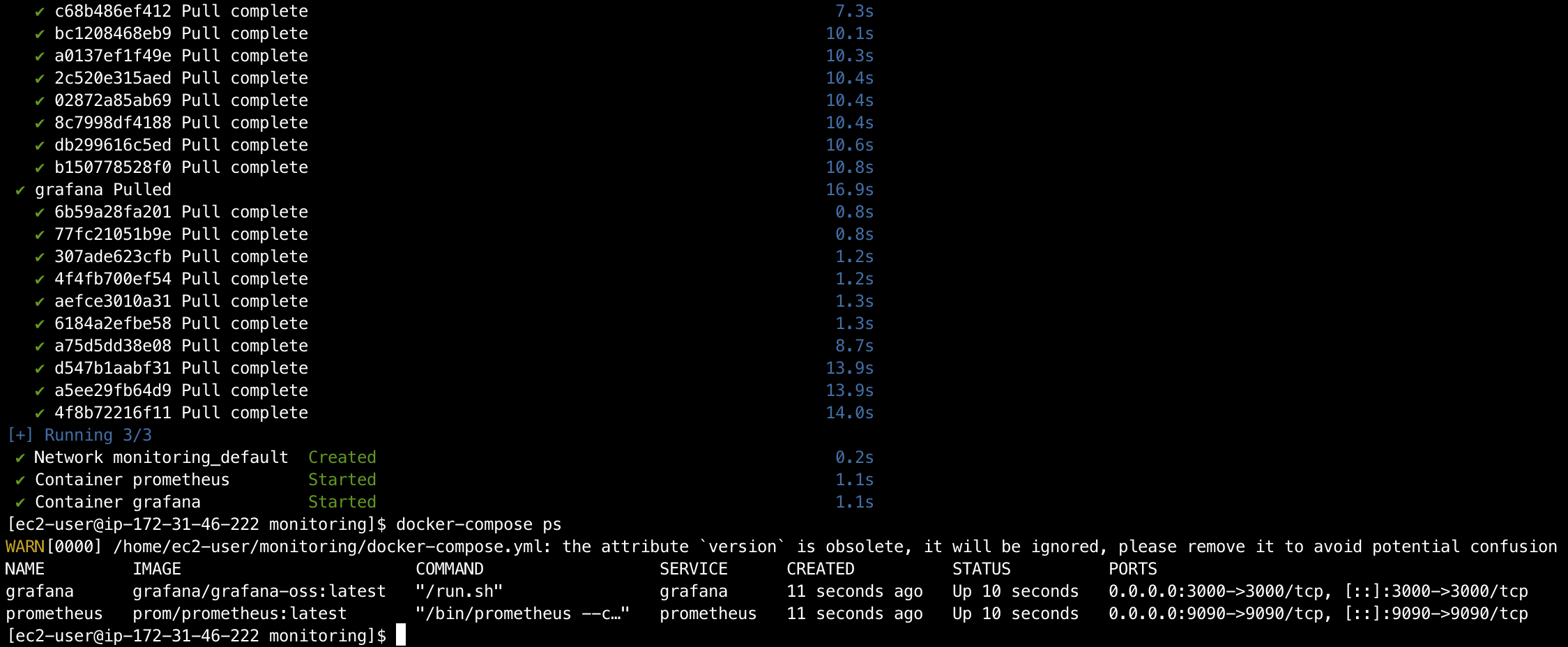
본격적인 구축에 앞서 전체적인 구조를 설계했다. 처음에는 비용과 관리의 편의성을 고려하여 기존 ‘어디GO’ EC2 인스턴스 위에 Prometheus와 Grafana를 Docker 컨테이너로 함께 띄우는 방식을 생각했다. 하나의 인스턴스에서 모든 것을 관리하니 간단해 보였다.
 초기 아키텍처 설계
초기 아키텍처 설계
하지만 이 방식에는 맹점이 존재했다. 만약 ‘어디GO’ 서버 인스턴스 자체 문제(커널 패닉, 메모리 부족 등)로 인스턴스가 다운된다면, 그 위에서 동작하던 Prometheus와 Grafana 역시 함께 멈춰버린다. 장애가 발생해서 원인을 파악해야 하는 가장 중요한 순간에 원인을 분석할 도구마저 잃게 되는 것이다. 이는 시스템 전체의 단일 장애점이 되는 구조였다.
모니터링 시스템 자체가 차지하는 리소스도 무시할 수 없었다. Prometheus가 데이터를 수집하고 Grafana가 이를 시각화하는 과정은 꾸준히 CPU와 메모리를 사용한다. 작은 t3.small 인스턴스에서 ‘어디GO’ 서비스와 리소스를 경쟁하게 되면, 트래픽이 몰리는 상황에서 서비스 성능에 악영향을 줄 수 있었다.
이러한 이유로, 나는 초기 구상안을 폐기하고 장애 격리와 안정성을 최우선 원칙으로 삼았다. 그 결과, ‘어디GO’ 서버와 완전히 분리된 별도의 모니터링 전용 서버를 두는 아키텍처를 최종적으로 채택했다. 이 구조는 비록 인스턴스 비용이 추가되지만, 그 이상의 안정성과 장애 대응 능력을 확보할 수 있는 현명한 트레이드오프라고 판단했다.
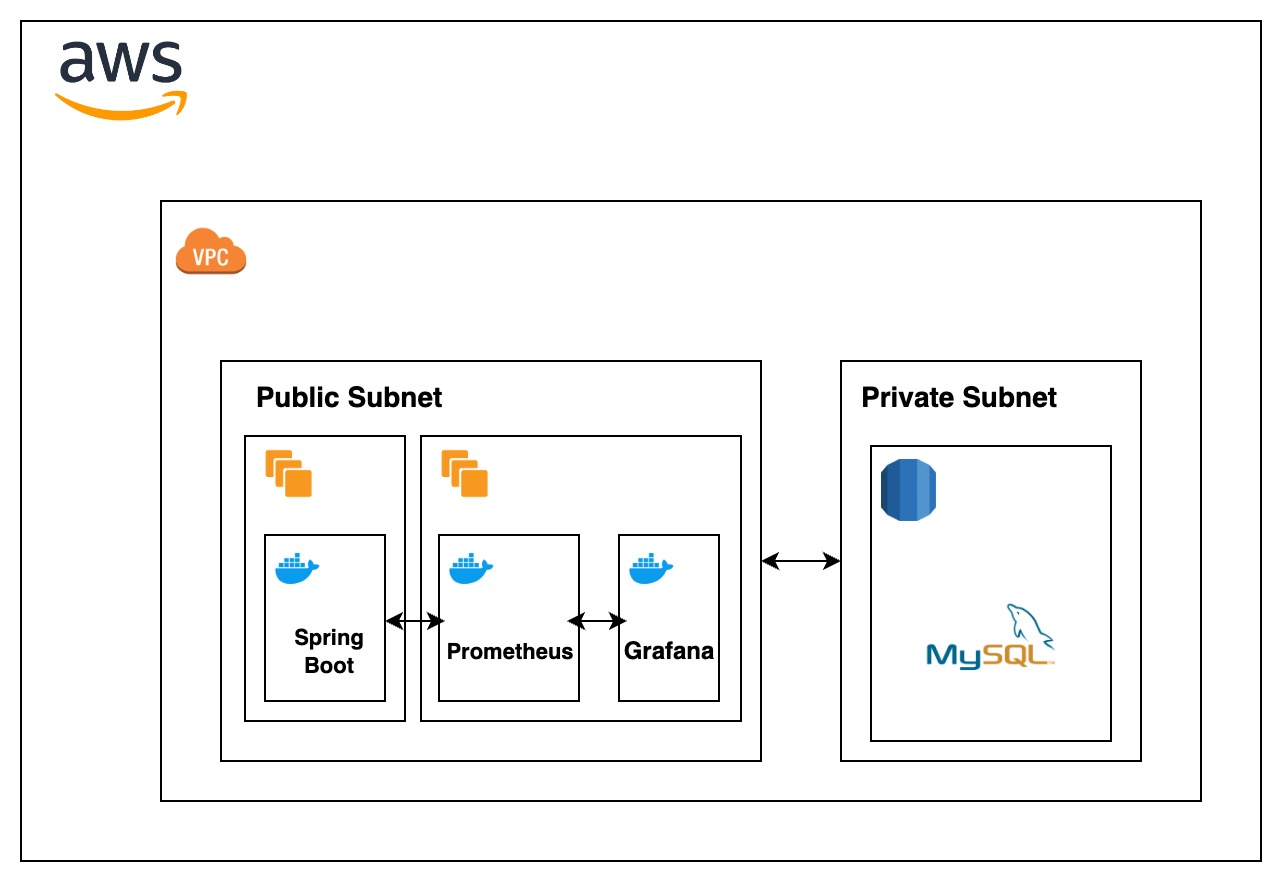 변경된 아키텍처 설계
변경된 아키텍처 설계
주요 흐름
- Metric 수집 대상 (
어디GO서버)- Node Exporter: 서버의 CPU, 메모리, 디스크 등 하드웨어 및 OS 지표(인프라 메트릭)를 수집하여 외부에 노출한다.
- Spring Boot Actuator: JVM, 스레드, GC 등 애플리케이션 내부 지표(애플리케이션 메트릭)를 수집하여 노출한다.
- 모니터링 서버
- Prometheus: 주기적으로
어디GO서버의 Node Exporter와 Actuator 엔드포인트에 접근하여 메트릭을 가져와 저장한다. - Grafana: Prometheus가 저장한 데이터를 시각화하여 사용자에게 대시보드로 보여준다.
- Prometheus: 주기적으로
두 서버는 동일한 VPC 내에 위치시켜, Private IP를 통해 안전하고 빠르게 통신하도록 구성했다.
모니터링 서버 구축
EC2 인스턴스 준비 및 Docker 환경 구성
가장 먼저 Prometheus와 Grafana가 설치될 전용 서버를 생성했다. 인스턴스는 t4g.micro를 선택하여 비용을 최소화했다.
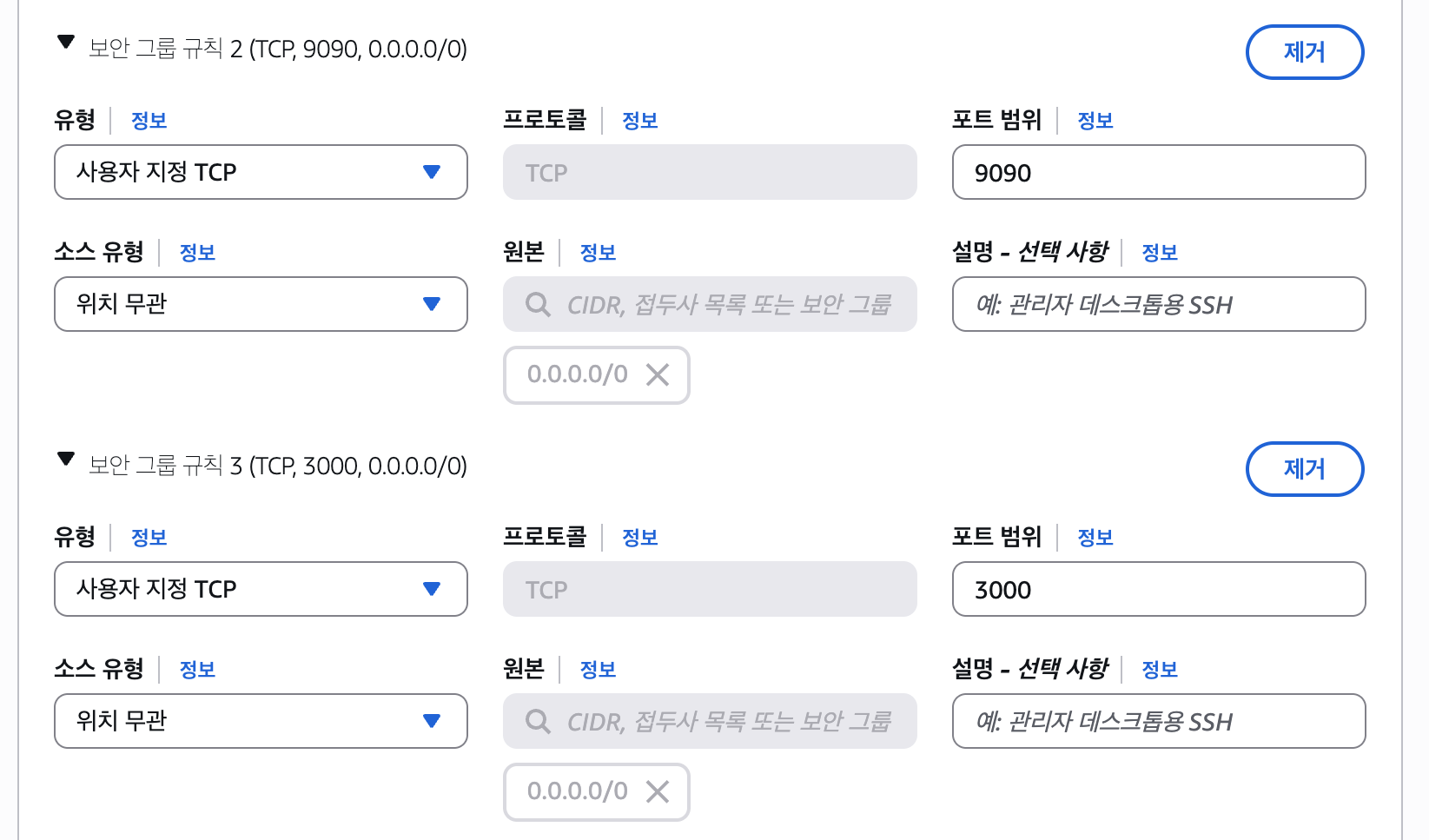
서버 생성 시 가장 중요한 것은 보안 그룹 설정이다. 외부에서 Prometheus와 Grafana 대시보드에 접근할 수 있도록 각각의 기본 포트인 9090과 3000번 포트를 인바운드 규칙에 추가했다. (SSH 접속을 위한 22번 포트 포함)
서버가 재부팅될 때마다 IP 주소가 바뀌는 것을 방지하기 위해 탄력적 IP(Elastic IP)를 할당하여 고정 IP를 부여했다.
서버 생성이 완료된 후, SSH로 접속하여 Docker와 Docker Compose를 설치했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 패키지 업데이트 및 Docker 설치
sudo dnf update -y
sudo dnf install docker -y
# Docker 서비스 시작 및 자동 실행 설정
sudo systemctl start docker
sudo systemctl enable docker
# ec2-user가 sudo 없이 docker 명령어를 사용하도록 그룹에 추가
sudo usermod -a -G docker ec2-user
# Docker Compose 설치
sudo curl -L "<https://github.com/docker/compose/releases/latest/download/docker-compose-$>(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose


Prometheus와 Grafana 실행
이제 준비된 Docker 환경 위에 Prometheus와 Grafana를 컨테이너로 실행할 차례다. 각 애플리케이션을 개별적으로 설치하고 관리하는 것은 번거롭기 때문에, docker-compose.yml 파일을 작성하여 두 서비스를 한번에 정의하고 실행했다.
먼저 Prometheus가 감시할 대상을 정의하는 설정 파일 prometheus.yml을 작성했다.
prometheus.yml
1
2
3
4
5
6
7
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
위 설정은 15초마다 Prometheus 자기 자신을 수집 대상으로 지정하는 기본 설정이다.
다음으로 두 서비스를 컨테이너로 띄우기 위한 docker-compose.yml 파일을 작성했다.
docker-compose.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
command:
- '--config.file=/etc/prometheus/prometheus.yml'
restart: unless-stopped
grafana:
image: grafana/grafana-oss:latest
container_name: grafana
ports:
- "3000:3000"
restart: unless-stopped
여기서 핵심은 volumes 설정인데, 위에서 작성한 prometheus.yml 파일(호스트 머신에 위치)을 컨테이너 내부의 설정 파일 경로로 연결해주는 것이다. 또한 restart: unless-stopped 옵션을 통해 서버가 예기치 않게 재부팅되더라도 모니터링 컨테이너가 자동으로 다시 실행되도록 설정했다.
이후 docker-compose up -d 명령어로 두 개의 컨테이너를 백그라운드에서 실행했다.