어디GO는 Android 전용 앱입니다. 링크를 통해 APK 파일을 다운로드하여 설치할 수 있습니다.
배경
최근 IT 연합 동아리 DND 13기에 참여했다. 우리 팀은 디자이너, 안드로이드 개발자, 백엔드 개발자 각각 2명씩, 총 6명으로 구성되었고, 나는 그중 백엔드 개발을 맡았다. 8주간의 활동 기간 동안 하나의 프로덕트를 완성하는 것이 목표였다.

우리 팀의 초기 아이디어는 ‘물가 상승 체감 서비스’였다. 하지만 논의 과정에서 ‘이 서비스가 사용자의 어떤 문제를 해결하는가?’라는 근본적인 질문에 부딪혔고, 팀원들과의 논의 끝에 프로젝트 방향을 수정했다. 최종적으로 오프라인 매장의 외식 가격과 공공데이터 기반의 상품 물가를 비교하는 서비스, ‘어디GO’를 개발하기로 결정했다.
프로젝트에서 내가 담당한 주요 역할은 다음과 같다.
- 인프라 설계 및 구축
- CI/CD 파이프라인 구축
- 상품 가격 탐색 기능 개발
- 데이터 수집 파이프라인 개발
핵심 기능
 |  |  |  |
| 1 | 2-1 | 2-2 | 2-3 |
서비스의 주요 기능은 외식 가격 비교와 상품 가격 탐색, 두 가지로 나뉜다.
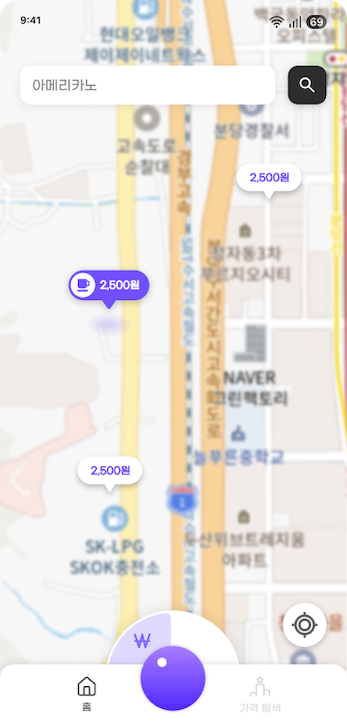
- 외식 가격 비교: 특정 메뉴(e.g., 아메리카노)를 기준으로 주변 상점의 가격 정보를 비교하여 제공한다.
- 상품 가격 탐색: 내가 담당한 파트로, 공공데이터(KAMIS)를 활용해 상품의 최신 가격을 제공한다.
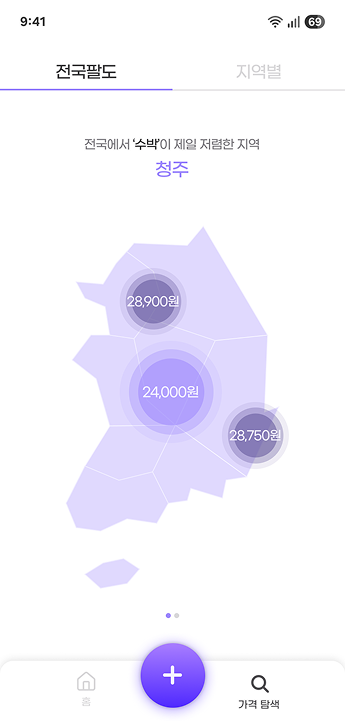
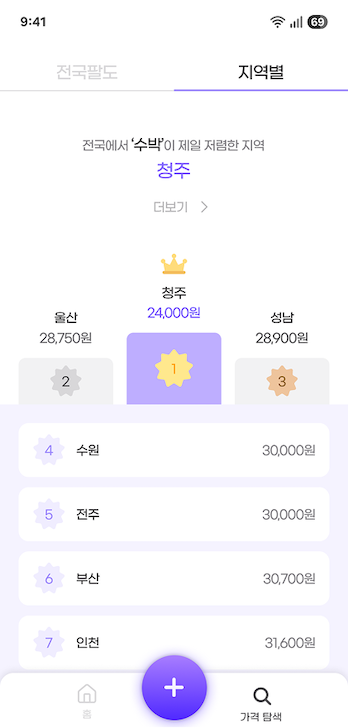
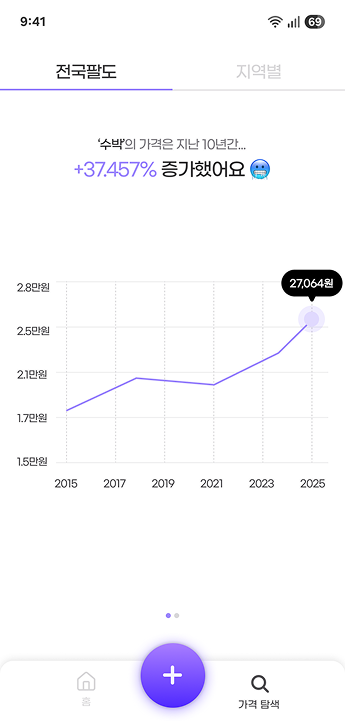
- 가격 랭킹: 특정 품목(e.g., 수박)의 최신 데이터를 기준으로 지역별 가격 순위를 제공한다.
- 가격 추이: 특정 품목의 지난 10년간 전국 평균 가격과 물가 상승률을 제공한다.
주요 기술 스택
안정적인 서비스 운영과 효율적인 개발을 목표로 기술 스택을 선정했다.
언어:
Kotlin(1.9.25)![kotlin]()
선택 이유:
팀 백엔드 개발자 모두 Java와 Kotlin에 익숙했지만, 8주라는 짧은 개발 기간을 고려했을 때 생산성과 안정성을 극대화하는 것이 중요했다.
- Null 안정성: Kotlin은 언어 레벨에서 Nullable 타입을 명시적으로 다루도록 설계되어 있다.
?연산자를 통해 컴파일 시점에NullPointerException(NPE)을 방지할 수 있어, Java에 비해 런타임 에러 발생 가능성을 크게 낮출 수 있다고 판단했다. - 코드 간결성: 데이터 클래스(Data Class), 확장 함수(Extension Function) 등 보일러플레이트 코드를 획기적으로 줄여주는 문법을 통해 더 적은 코드로 비즈니스 로직을 표현할 수 있었다. 이는 코드 가독성을 높이고 개발 속도를 향상시키는 데 직접적으로 기여했다.
- 완벽한 호환성: 기존 Spring 및 Java 생태계와 100% 호환되어, 팀원들이 가진 Java/Spring 경험을 그대로 활용하는 데 전혀 문제가 없었다.
- Null 안정성: Kotlin은 언어 레벨에서 Nullable 타입을 명시적으로 다루도록 설계되어 있다.
프레임워크:
Spring Boot(3.5.4)![spring boot]()
![spring boot version]()
- 선택 이유:
- 개발 생산성: 팀원 모두에게 가장 익숙한 프레임워크로, 내장 WAS와 강력한 자동 설정(Auto-Configuration) 덕분에 복잡한 초기 설정 없이 비즈니스 로직 개발에 즉시 집중할 수 있었다.
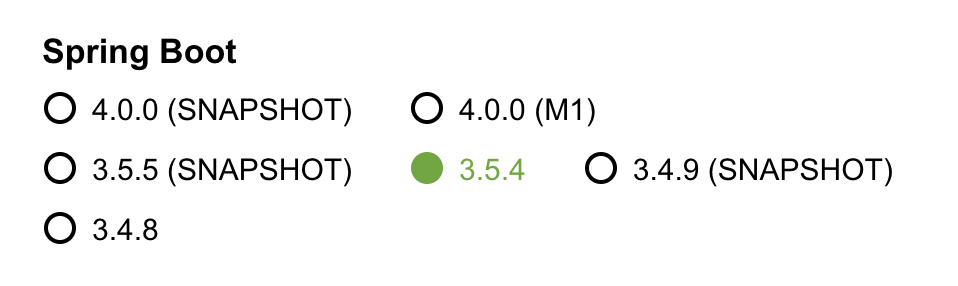
- 버전 선택 과정: 처음엔 최신인 Kotlin 2.x를 사용하자고 논의를 했다. 하지만 이를 위해서는 Spring Boot 4.0.0 버전을 사용해야 했는데, 해당 버전은 정식 출시되지 않은 마일스톤(Milestone) 버전이라 단기 프로젝트의 안정성을 담보하기 어렵다고 판단했다. 따라서, 정식 출시된 버전 중 최신인 Spring Boot 3.5.4와 이에 맞는 Kotlin 1.9.25 버전을 최종적으로 선택했다. 이는 레퍼런스를 확보하고 예측 불가능한 이슈를 최소화하기 위한 결정이었다.
- 선택 이유:
데이터베이스 & ORM:
MySQL&Spring Data JPA![mysql]()
![jpa]()
- 선택 이유:
- MySQL: 수집하는 가격 데이터는 명확한 스키마를 가진 정형 데이터이므로 관계형 데이터베이스가 적합했다. AWS RDS에서 완전 관리형으로 제공되어 운영 부담이 적고, 가장 대중적인 RDBMS라 참고 자료가 풍부한 점도 고려했다.
- Spring Data JPA: 반복적인 CRUD 쿼리 작성을 최소화하고, 객체 지향적으로 데이터에 접근할 수 있게 해 주었다.
@Entity선언만으로 테이블 관리가 가능하고, 복잡한 조회 조건은 Query Method나@Query를 통해 유연하게 처리할 수 있어 개발 속도에 크게 기여했다.
- 선택 이유:
데이터 수집:
Spring Batch![batch]()
- 선택 이유:
- 대용량 처리 안정성: 단순히 스케줄러로 API를 호출하는 것을 넘어, 수천 건의 데이터를 처리하는 과정에서 에러가 발생했을 때의 대응이 중요했다. Spring Batch는 Job/Step 구조를 통해 트랜잭션 단위로 작업을 나누고, 실패 시 특정 지점부터 재시작(Restart)하는 기능을 제공하여 데이터 무결성과 처리 안정성을 보장해 주었다.
- Chunk 지향 처리: 데이터를 일정 크기(Chunk)로 묶어 한 번에 읽고, 처리하고, 쓰는 모델은 대용량 데이터를 다룰 때 메모리 사용량을 최적화하고 성능을 높이는 데 효과적이었다.
- 선택 이유:
- API 통신:
WebClient(on Reactor Netty)- 선택 이유:
- 비동기/논블로킹: 외부 API(KAMIS) 호출은 네트워크 I/O가 발생하는 대표적인 작업이다. 동기 방식의
RestTemplate과 달리,WebClient는 요청 후 응답을 기다리는 동안 스레드를 차단하지 않아 더 적은 스레드로 높은 동시성을 처리할 수 있다. 이는 한정된 자원의 EC2 인스턴스에서 시스템 효율을 극대화하기 위한 선택이었다. - 최신 기술 스택: Spring 5부터 공식적으로 권장되는 HTTP 클라이언트이다.
- 비동기/논블로킹: 외부 API(KAMIS) 호출은 네트워크 I/O가 발생하는 대표적인 작업이다. 동기 방식의
- 선택 이유:
- 인프라 및 배포:
AWS,Docker,GitHub Actions,ECR- 선택 이유:
- AWS: 가장 널리 사용되는 클라우드 서비스로, 필요한 인프라(EC2, RDS, S3 등)를 빠르고 유연하게 구축할 수 있었다.
- Docker: 개발, 테스트, 운영 환경의 차이에서 오는 문제를 원천적으로 차단하고, 배포의 일관성을 확보하기 위해 애플리케이션을 컨테이너화했다.
- GitHub Actions: 코드 변경 사항이
develop브랜치에 푸시될 때마다 자동으로 Docker 이미지를 빌드하고 ECR에 푸시, EC2에 배포하는 CI/CD 파이프라인을 구축했다. 이를 통해 수동 배포 과정에서 발생할 수 있는 실수를 줄이고, 개발자가 코드에만 집중할 수 있는 환경을 만들었다. - ECR
ECR vs Docker Hub
ECR과 Docker Hub는 모두 컨테이너 이미지를 저장하는 레지스트리지만, AWS 환경에서는 ECR을 사용하는 것이 몇 가지 명확한 이점을 제공한다.
- 보안 및 권한 관리: ECR은 AWS IAM과 통합되어, 역할을 기반으로 한 세분화된 접근 제어가 가능하다. 이는 단순 계정 기반의 Docker Hub보다 높은 수준의 보안을 제공한다.
- 성능: EC2 인스턴스에서 이미지를 다운로드할 때 AWS 내부 네트워크를 사용하므로 더 빠르다.
- AWS 생태계와의 통합: 향후 ECS, EKS 등 다른 AWS 컨테이너 서비스로 확장할 경우 유연한 아키텍처 구성에 유리하다.
이러한 이유로, AWS 기반의 파이프라인을 구축하는 이번 과제에서는 ECR을 사용하게 되었다.
- 선택 이유:





백엔드 시스템 설계
시스템 아키텍처
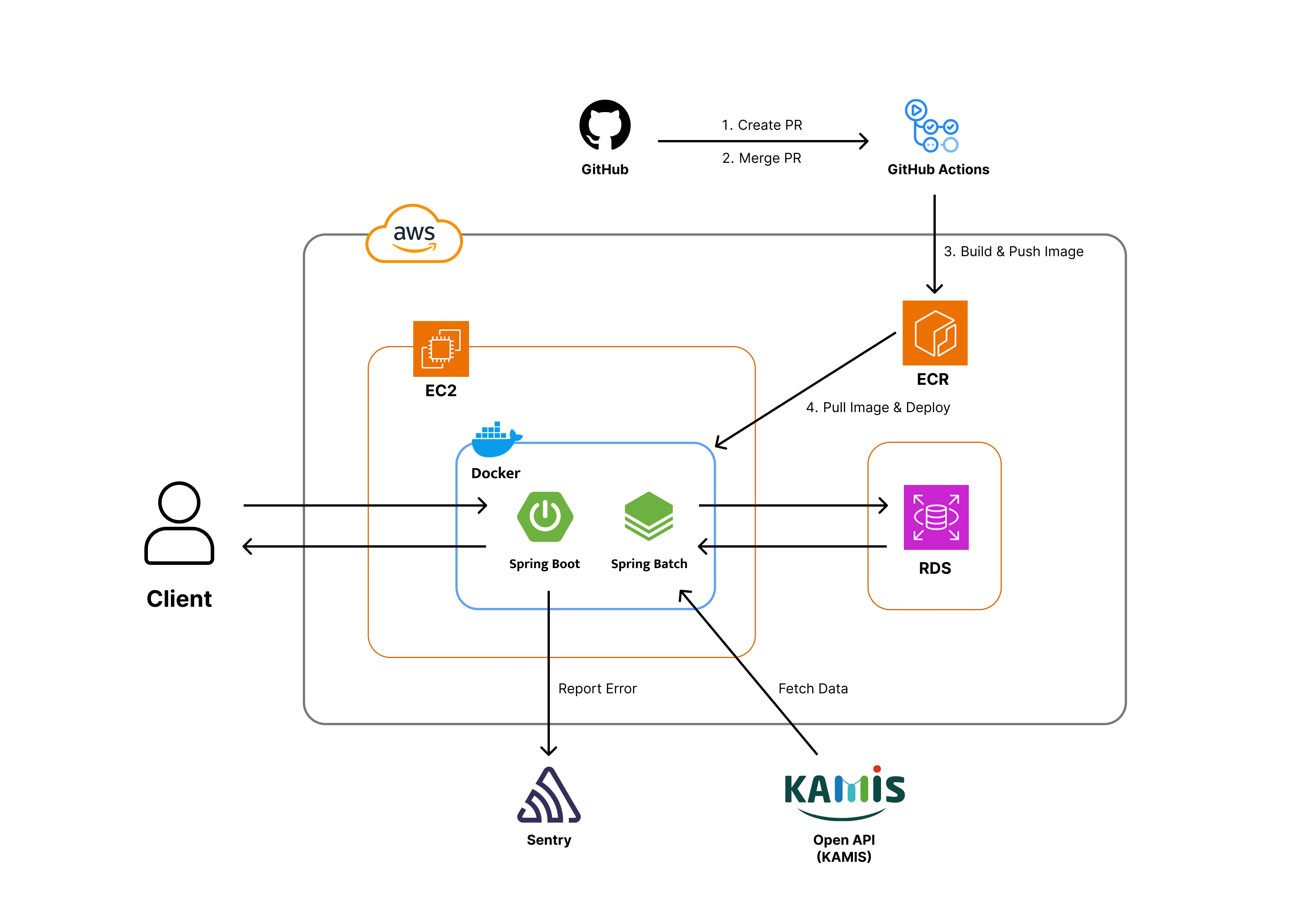
프로젝트의 전체 인프라 구조이다. 보안을 최우선으로 고려하여 데이터베이스(RDS)는 Private Subnet 내에 배치했고, 애플리케이션 서버(EC2)를 통해서만 접근 가능하도록 네트워크를 구성했다.
API 설계
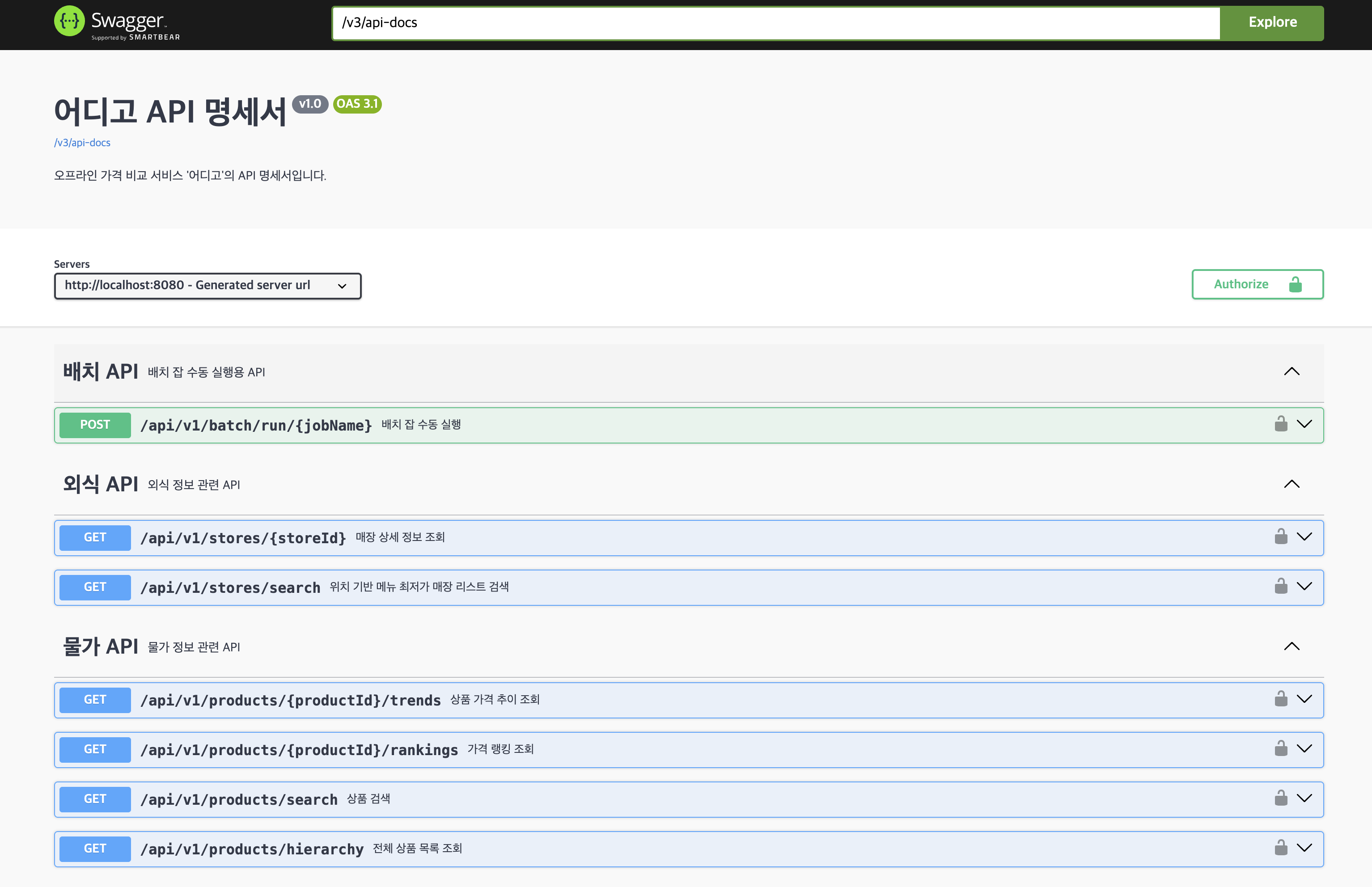
프론트엔드와의 효율적인 협업을 위해 API-First 접근 방식을 따랐다. Springdoc OpenAPI(Swagger)를 통해 API 명세를 먼저 정의하고 공유하여 개발 병목을 최소화했다.
또한, 가격 정보는 상품에 종속된다는 관계를 명확히 하기 위해 /products/{productId}/rankings 와 같이 RESTful 원칙에 따라 엔드포인트를 설계했다.
데이터 수집 파이프라인
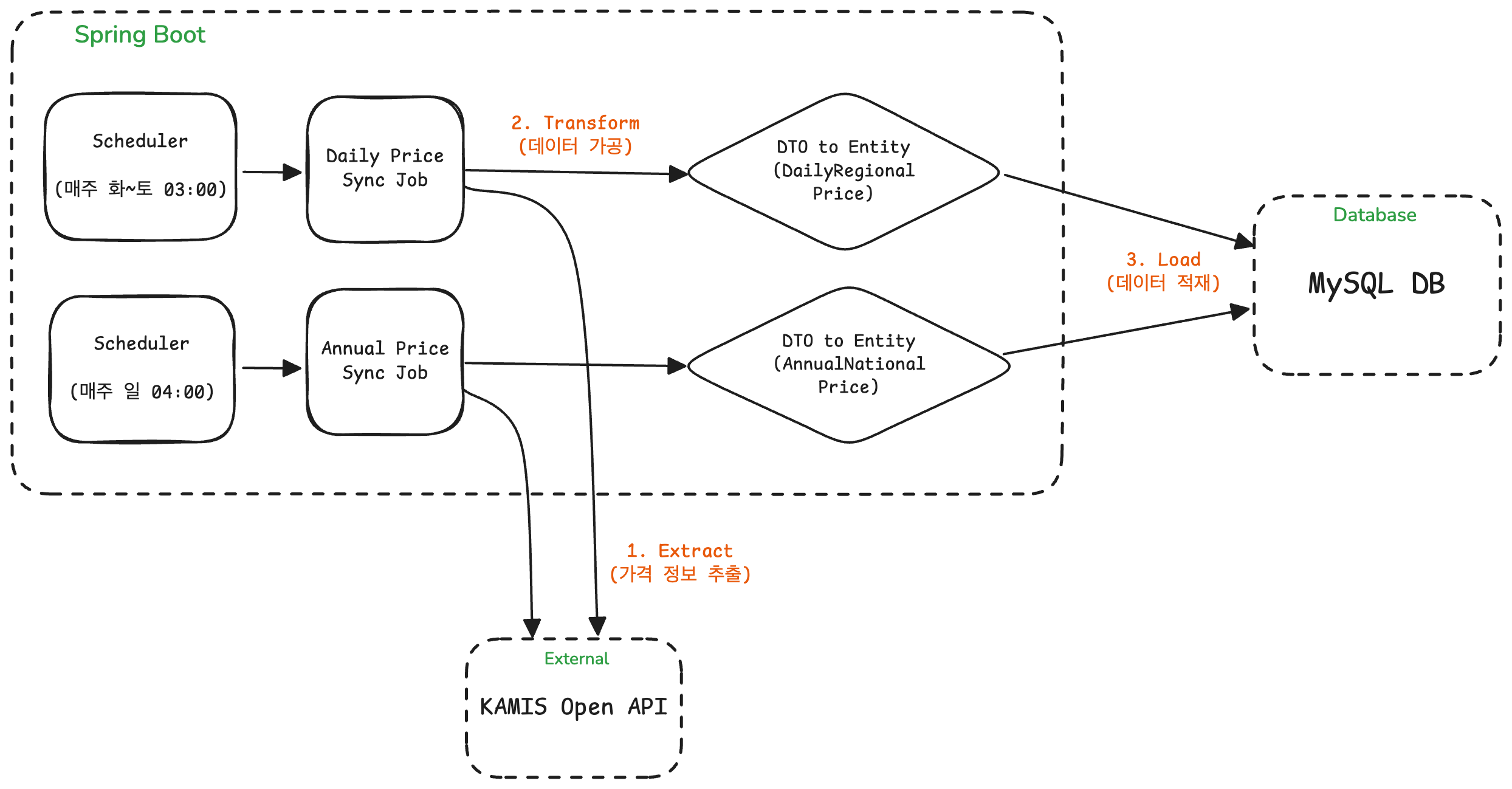
서비스의 핵심인 최신 가격 데이터 수집은 매일 새벽 Spring Batch Job을 통해 수행됐다. 이 파이프라인은 스케줄러에 의해 자동으로 실행되며, KAMIS Open API로부터 데이터를 조회하여 DB에 저장한다.
마치며
4주간의 MVP 개발 기간 동안 핵심 기능을 구현하고 배포까지 완료했다. 이 과정을 통해 클라우드 인프라 설계부터 CI/CD, 데이터 배치 처리까지 백엔드 개발의 전반적인 사이클을 경험할 수 있었다.
시간 제약으로 인해 Flyway를 이용한 DB 마이그레이션 자동화나 Prometheus, Grafana 기반의 모니터링 시스템 구축은 추후 과제로 남겨두었다.
이어질 글에서는 프로젝트에 대해 더 자세히 이야기해보려 한다.